Python课程笔记(二)
课程笔记:
第六章:数据结构(一)
Python提供了功能强大的内置数据结构。
- 字符串
- 列表
- 元组
- 字典
- 集合
Python中,前三个:字符串、列表和元组都属于序列。
序列有一些通用的操作。包括:
索引(indexing)
切片(slicing)
连接(adding)
重复(multiplying)
检查某个元素是否属于序列的成员(成员资格)
计算序列长度
找出最大元素和最小元素等。
一、序列相关操作:
- 标准类型运算符:
- 值比较
- 对象身份比较
- 布尔运算
- 序列类型运算符:
- 获取
- 重复
- 连接
- 判断
- 内置函数:
- 序列类型转换内置函数
- 序列类型其他常用内置函数
标准类型运算符:
- 对象值比较:(<、<=、>、>=、==、!=)
- 对象身份比较(is 、is not)
- 布尔运算(not、and、or)
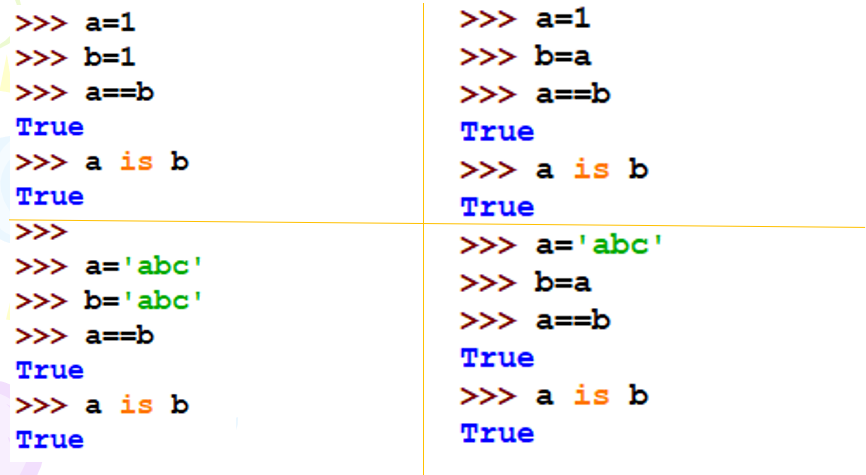
关于对象的值比较与身份比较说明:对象身份比较的相等指的是值和地址均相同。
对于小整数池([-5, 256])的数值以及字符串来说,值和身份比较结果相同;
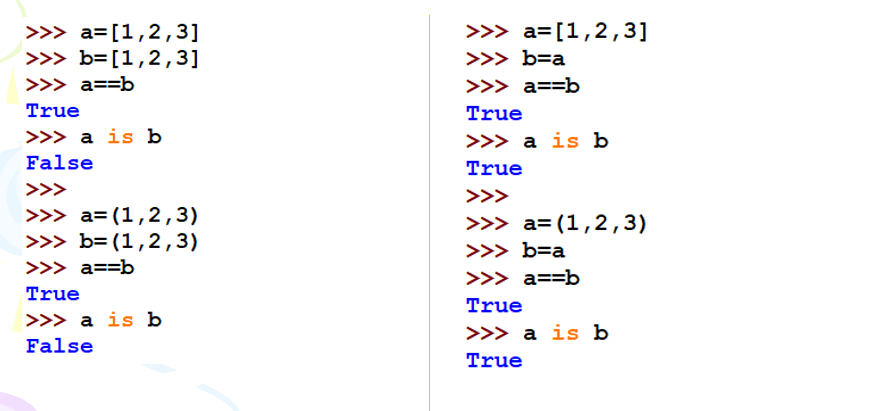
对于非小整数池的数值及列表、元组、字典和集合(所谓“集合型数据类型”),值比较和身份比较结果不同。
小整数池数值及字符串的值比较与身份比较示例:
非小整数池数值的值比较及身份比较示例:

集合型数据的值比较与身份比较示例:
也就是说对于小整数池、字符串,他们只要值相同,内存地址也是相同的,所以值和身份比较结果相同
对于非小整数池、集合型数据,他们的值相同,但是内存地址不相同,所以值和身份比较结果可能不同
- 如果是a和b单独定义相同的值,只是值相同,则地址是不同的,所以身份比较结果不同
- 如果是a先定义,b直接定义为b=a,则值和地址也是相同的,所以身份比较结果这时候是相同的
序列类型运算符:
s、t为序列,x为元素,n为正整数
成员资格判断
- x in s
- x not in s
序列连接
s+t两个序列首尾相接s*n、n*s序列重复n次
序列切片(截取子序列)
- s [beg: end : step]
序列的索引:
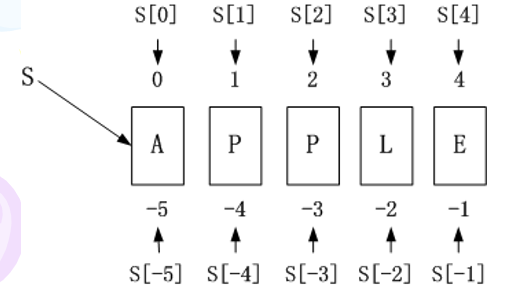
序列中的所有元素都有编号。从0开始递增。这些元素可以通过编号分别访问。索引有正索引和负索引,可根据实际情况选用。
例如:字符串’apple’的正索引和负索引:

序列切片(截取子序列)
s [ beg : end : step ]说明:截取的子序列中包含的内容是
s中从beg至end-1(不包括end)位置上的元素;省略beg,则表示从s的开始处进行子序列截取,等价于
s [ 0 : end ];省略end,则表示截取的子序列中包含从beg位置开始到最后一个元素之间的字符(包括最后一个元素);
beg和end都省略则表示子序列中包含s中所有元素;
step表示截取子序列是间隔的步长,默认值为1。若为负值,则表示逆向截取。
序列类型转换内置函数:
str():转为字符串
list():列表
- list() -> new empty list
- list(iterable) -> new list initialized from iterable’s items
tuple():元组
- tuple() -> empty tuple
- tuple(iterable) -> tuple initialized from iterable’s items

其中:
list((1,2,3,4,5))是元组转为列表
tuple([1,2,3,4,5])是列表转为元组
序列类型其他常用内置函数:

sorted()是排序,输出是先大写字母排序,再小写字母排序
示例:
enumerate()函数:

zip()函数:

reversed()函数:

sorted()函数:

其中
set()函数是集合函数,可以自动过滤掉集合中相同的元素
二、字符串格式化和常用方法
在Python中,字符串是除数字外最重要的数据类型。
可充分利用
索引和切片,用于从字符串中提取子串。虽然Python字符串提供了众多实用的函数,但实际处理字符串时,常常需要更强大的工具。Python提供了一个第三方库re,进行正则表达式处理,用于处理复杂字符串。
字符串格式化
在使用print语句输出数据时,可以按照定制的格式进行输出,Python提供了一些字符串格式化方法:
- 类似C语言的格式化方法,使用
% - format()方法
- 其他方法
重点掌握format方法使用
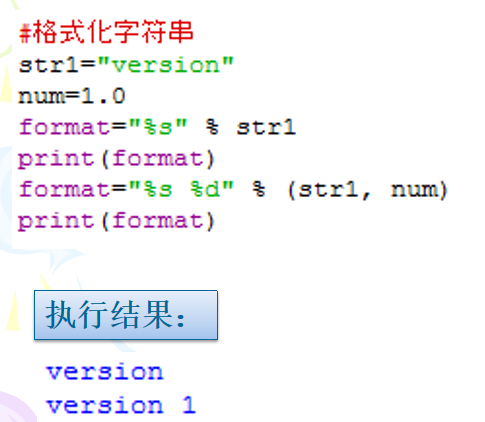
1、使用%格式化字符串
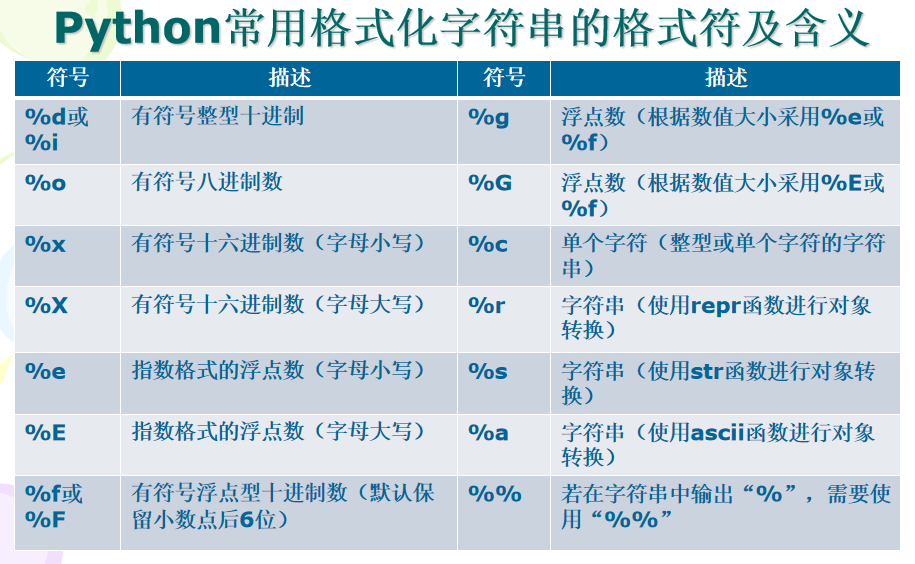
C语言使用函数printf()格式化输出结果,Python也提供了类似功能。Python将若干值插入带有“%”标记的字符串中,从而可以按照指定格式输出字符串。语法:
1 | "%wC" % value |
其余的格式符:
若输出的是字符串,可以加入宽度和对齐方式:
- 减号(左对齐,默认右对齐)
若输出的是数值,在字段宽度和精度之间还可以放置一个“标志”,该标志可以是:
- 加号(可显示数字的正负号)
- 减号(左对齐,默认右对齐)
- 零(表示数字空位将会用0填充)
- 空格(表示正数前加空格)
示例:

2、使用format方法格式化字符串
Python推荐使用format()方法,相比C语言风格格式化方法,该方法功能更强、更直观、更容易格式化各种数据类型。
format方法的基本使用格式:
1 | <模板字符串>.format(<逗号分隔的参数>) |
其中:
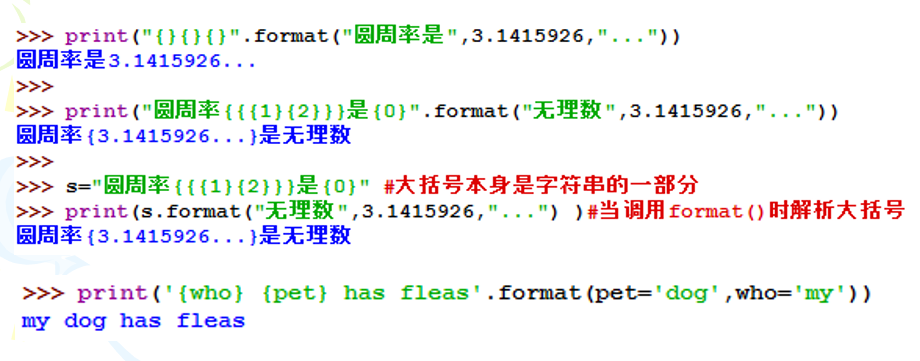
<模板字符串>由一系列的槽组成,用来控制字符串中嵌入值出现的位置,其基本思想是将format()方法的<逗号分隔的参数>中的参数按照序号关系替换到<模板字符串>的槽中;
槽用大括号
{}表示,如果大括号中没有序号,则按照出现顺序替换;如果大括号中指定了使用参数的序号,按照序号对应参数替换;槽中还可以使用关键字参数。
不使用序号情况:

使用序号的情况:

示例:
带有格式信息的槽:
format()方法中<模板字符串>的槽除了包括参数序号,还可以包括:格式控制信息。此时,槽的内部格式为:
1 | {<参数序号>: <格式控制标记>} |
槽中格式控制标记的字段:

<格式控制标记> 包括:<填充>、<对齐>、<宽度>、,、<.精度>、<类型> 6 个字段(须按此顺序排列),这些字段都是可选的,可以组合使用。
字段功能:<填充>、<对齐>和<宽度>是3个相关字段。
<宽度>指当前槽的设定输出字符宽度,如果该槽对应的format()参数长度比<宽度>设定值大,则使用参数实际长度。如果该值的实际位数小于指定宽度,则位数将被默认以空格字符补充。
<对齐>指参数在<宽度>内输出时的对齐方式,分别使用<、>和^三个符号表示左对齐、右对齐和居中对齐。默认为左对齐。
<填充>指<宽度>内除了参数外的字符采用什么方式表示,默认采用空格,可以通过<填充>更换
示例:
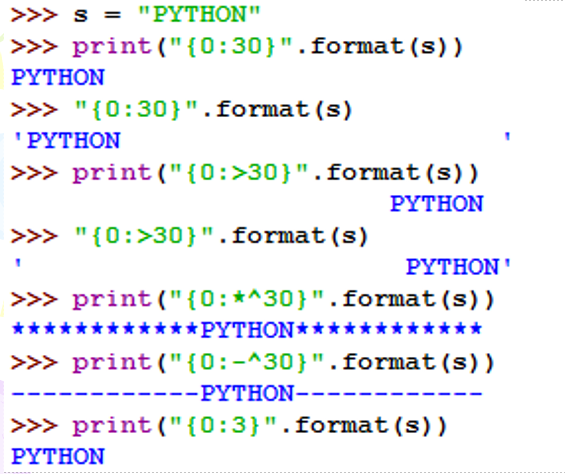
其中上面表示的
{0:30}这个0是序号,表示第0个参数,即s字符串填在0处
<格式控制标记>中逗号(,)用于显示数字的千位分隔符。
示例:
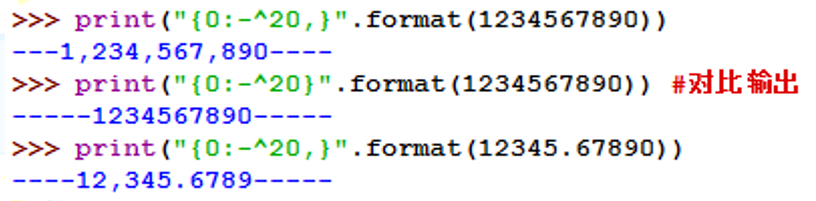
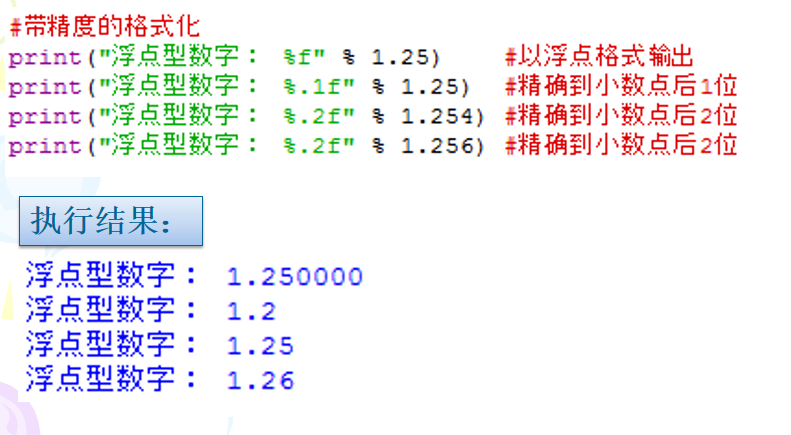
<.精度>表示两个含义,由小数点(.)开头。
对于浮点数,精度表示小数部分输出的有效位数;
对于字符串,精度表示输出的最大长度。
示例:
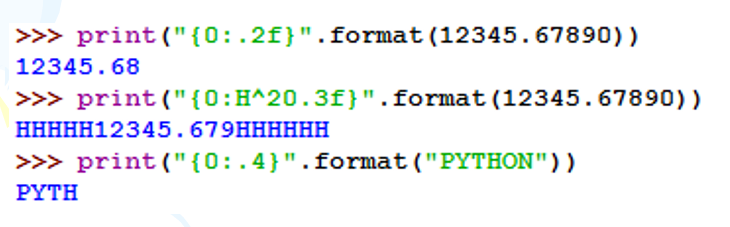
<类型>表示输出整数和浮点数类型的格式规则。
对于整数类型,输出格式包括6种:
- b: 输出整数的二进制格式;
- c: 输出整数对应的 Unicode 字符;
- d: 输出整数的十进制格式;
- o: 输出整数的八进制格式;
- x: 输出整数的小写十六进制格式;
- X: 输出整数的大写十六进制格式。
对于浮点数类型,输出格式包括4种:
- e: 输出浮点数对应的小写字母 e 的指数形式;
- E: 输出浮点数对应的大写字母 E 的指数形式;
- f: 输出浮点数的标准浮点形式;
- %: 输出浮点数的百分数形式。
示例:

另:字符串的转义字符
计算机中存在可见字符与不可见字符:
可见字符指键盘上的字母、数字和符号。
不可见字符是指换行、回车、制表符等字符。对于不可见字符,Python使用的方法类似于C语言,都是使用\作为转义字符。
Python还提供了函数strip()、lstrip()、rstrip()去除字符串中的转义字符。
下面是8个常用转义字符及其含义:
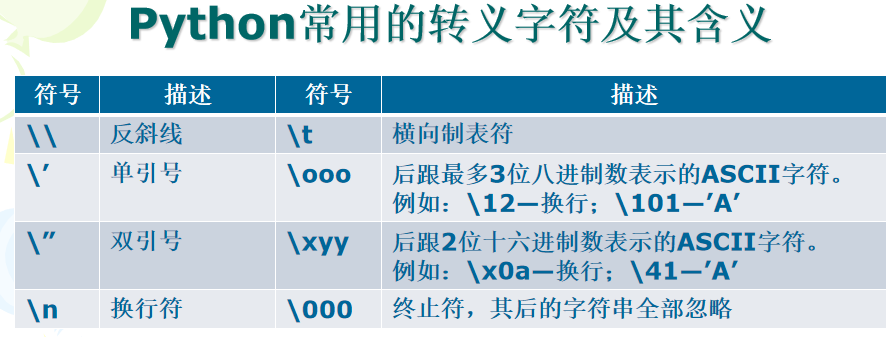
示例:

常用字符串方法
Python字符串自带了大量很有用的方法(字符串类内定义的函数),可调用dir函数并将参数指定为任何字符串(如:dir(’ ’))来查看它们。虽无必要准确记住所有字符串方法功能,但最好有个大致了解,这样有益于需要时去查询具体使用方法。
字符串方法的详细介绍可参阅其文档字符串或Python在线文档。这里介绍常用的字符串方法。
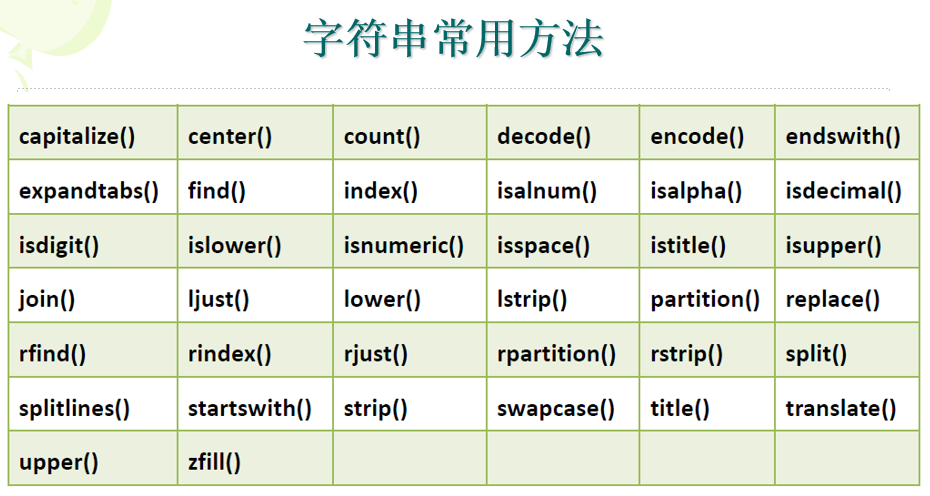
重点复习:s.find()、s.rfind()、s.index()、s.rindex、s.replace()、s.split()、s.strip()、s.lower()、s.upper()
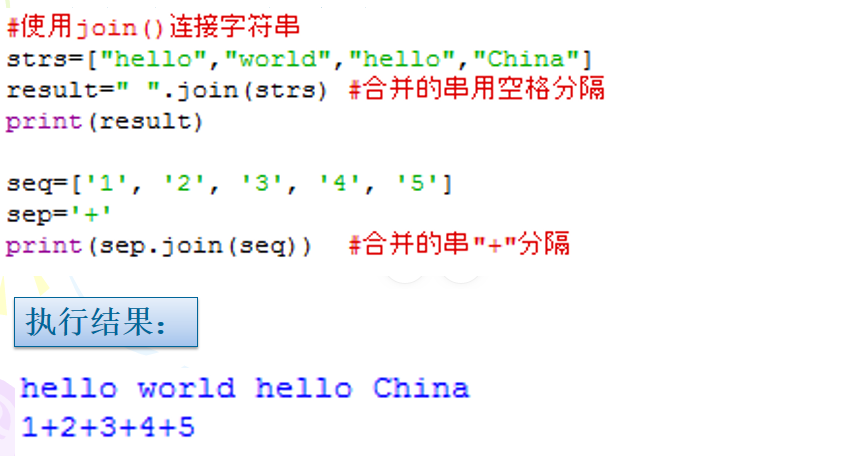
字符串合并的其他方法:join
1、字符串测试
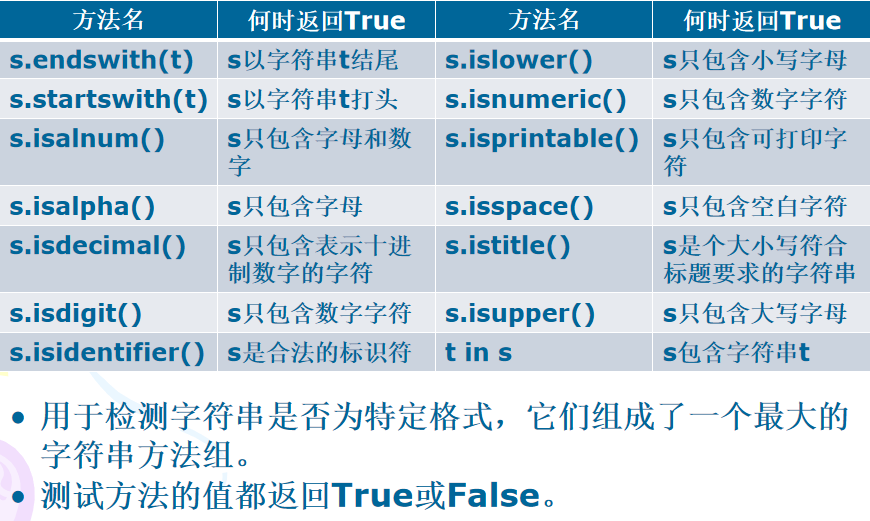
示例:
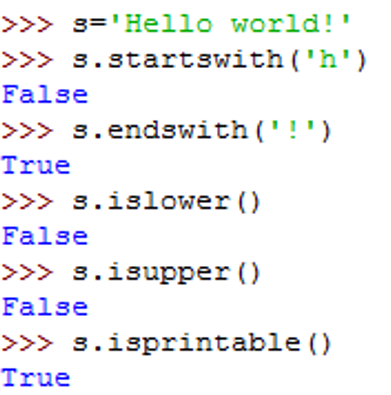
2、字符串的查找

示例:
3、字符串的替换

示例:

4、字符串拆分
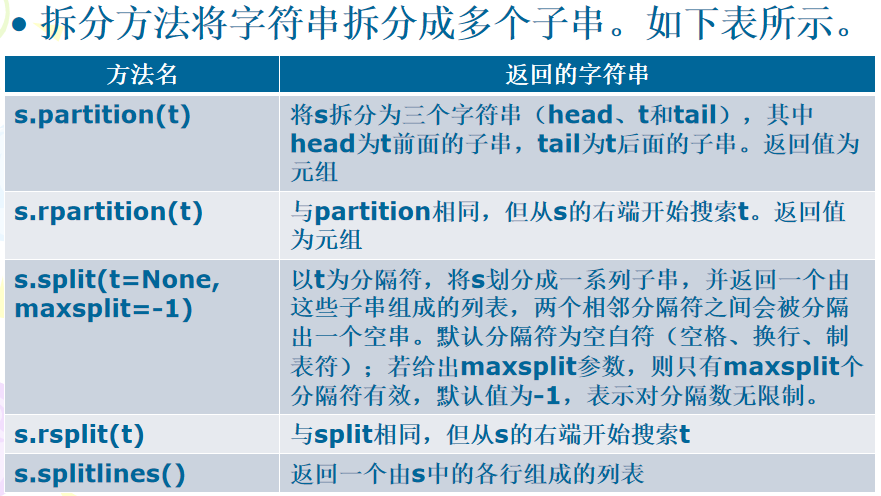
示例1:
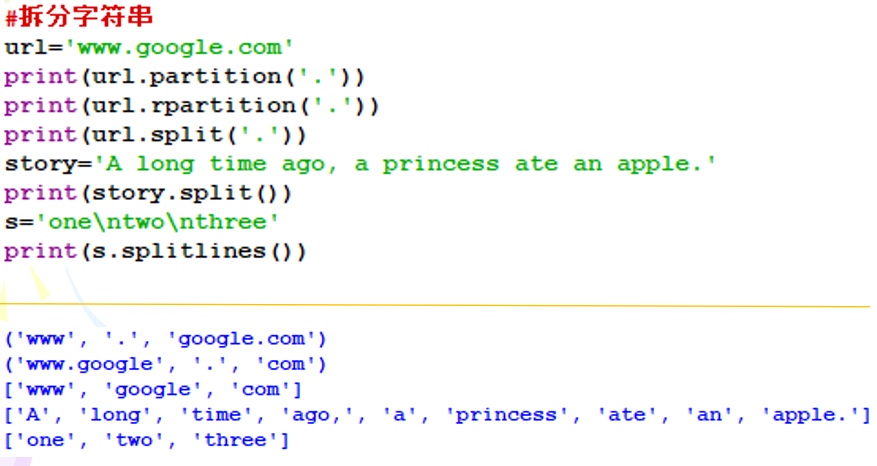
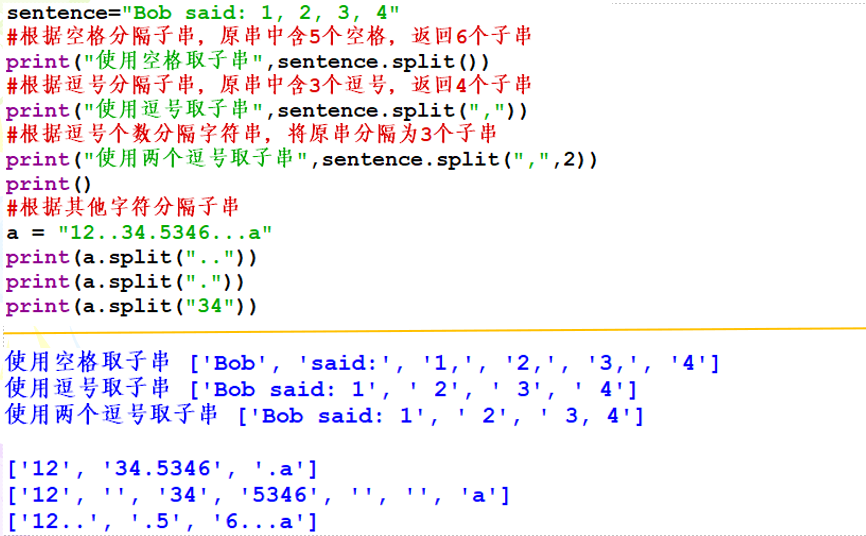
示例2:使用split()方法分隔子串
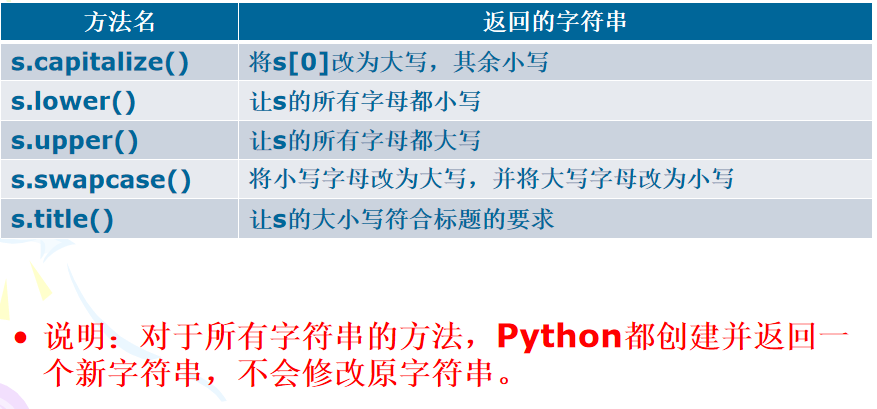
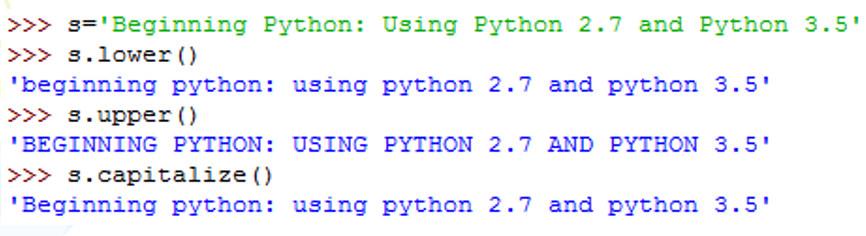
5、改变大小写
示例1:
示例2:如有以下形式的一些句子: What do you think of this saying “No pain, No gain”? 对于句子中双引号中的内容,首先判断其是否满足标题格式,不管满足与否最终都将其转换为标题格式输出。
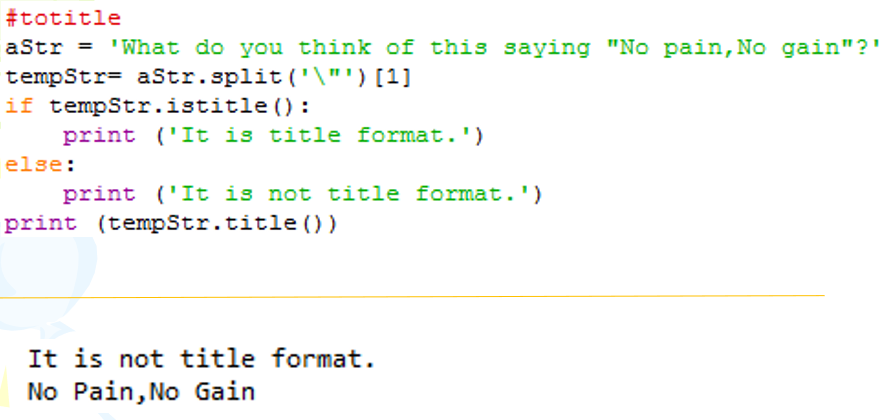
tempStr= aStr.split('\"')[1]首先split以双引号
"为分隔符分割成列表,然后取[1]号元素,也就是第二个元素:No pain, No gain,然后
title之后变成:No Pain, No Gain
6、设置字符串格式
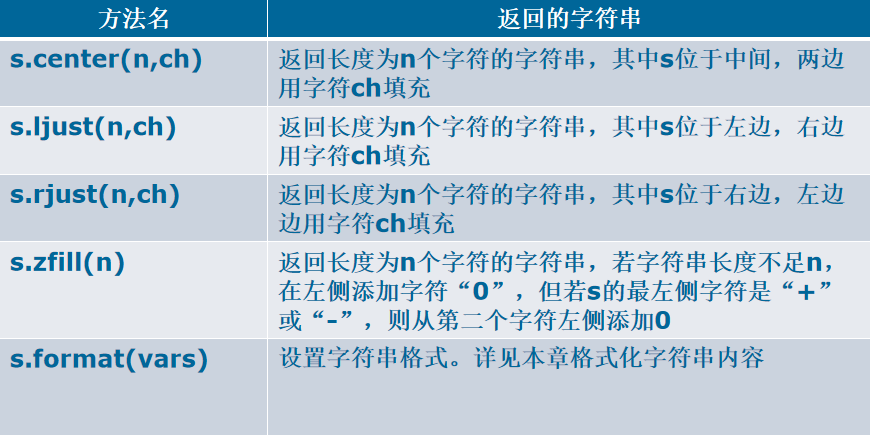
示例:

7、字符串剥除
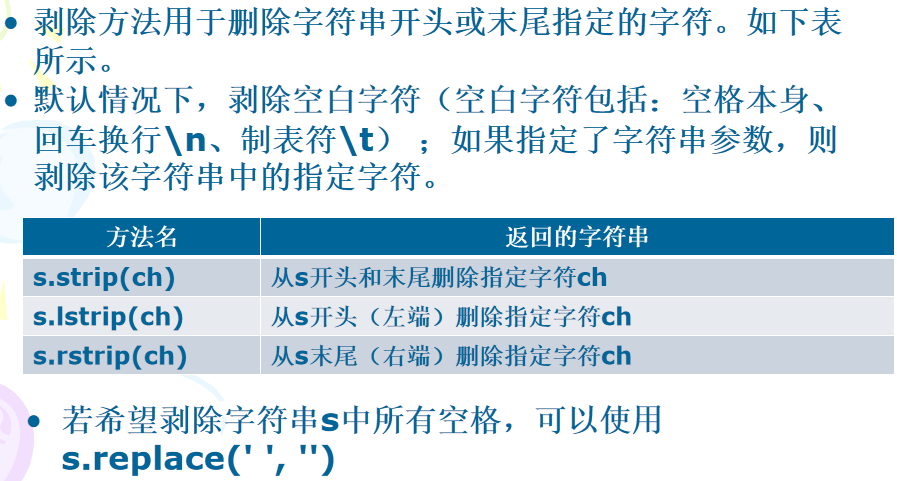
示例1:字符串剔除
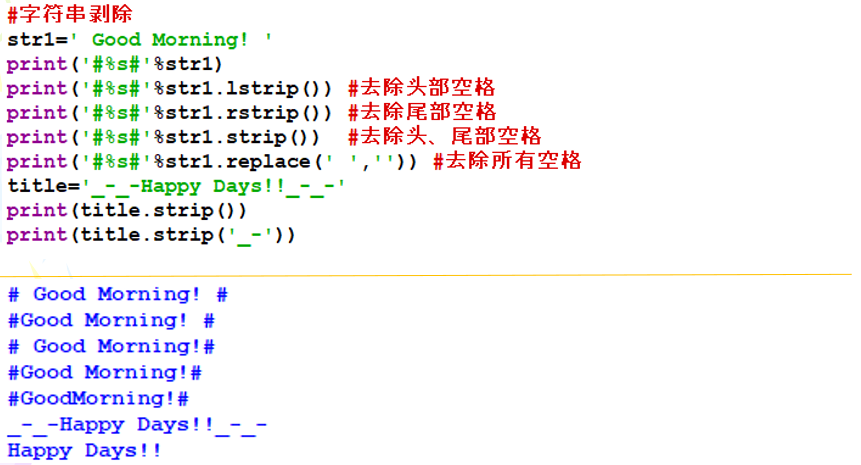
示例2:去除空白字符

8、字符串比较

示例:

9、字符串的合并

join方法:
- 格式:
S.join(iterable) -> str - 功能:Return a string which is the concatenation of the strings in the iterable. The separator between elements is S.
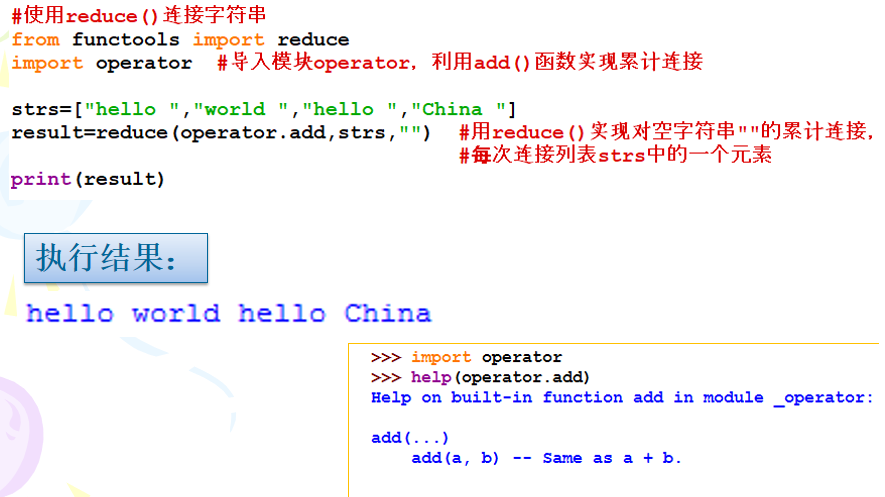
reduce方法:
- 格式:
reduce(function, sequence[, initial]) -> value - 功能:Apply a function of two arguments cumulatively to the items of a sequence, from left to right, so as to reduce the sequence to a single value. For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates ((((1+2)+3)+4)+5). If initial is present, it is placed before the items of the sequence in the calculation, and serves as a default when the sequence is empty.
示例:
10、字符串与日期的转换
在实际应用中,经常需要将日期类型与字符串类型互相转换。Python提供了datetime模块处理日期和时间。
时间到字符串转换:
- 声明:日期类型变量
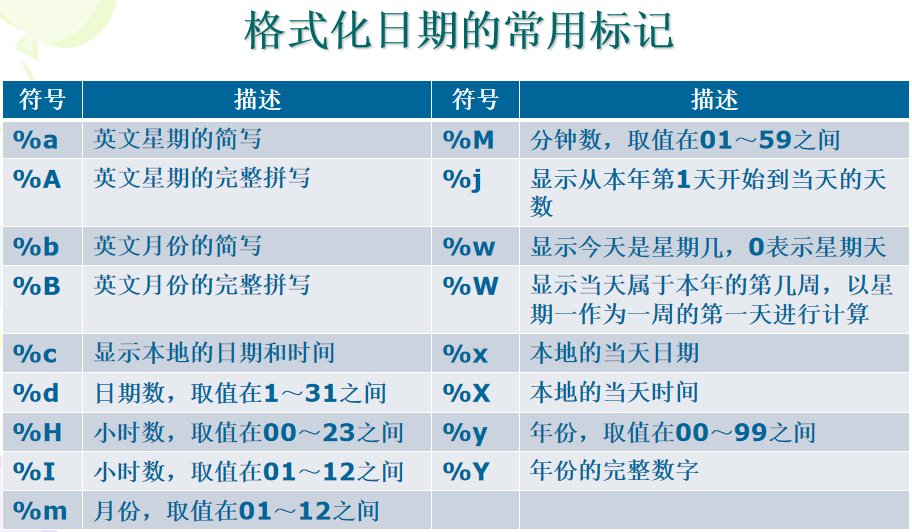
.strftime(format)->string - 说明:参数format表示格式化日期的特殊字符。例如:“%Y-%m-%d”相当于“yyyy-mm-dd”,函数返回一个表示时间的字符串。
字符串到时间的转换:
- 声明为:
strptime(string, format)->struct_time - 说明:函数返回一个date类型的变量。format含义同前
示例1:

示例2:

第三方库Re:正则表达式
看课件
第七章:数据结构(二)
集合型数据类型的种类:列表、元组、字典、集合
列表
列表是Python中非常重要的数据类型,通常作为函数的返回类型;列表由一组元素组成。列表可包含任何类型的值:数字、字符串甚至序列;
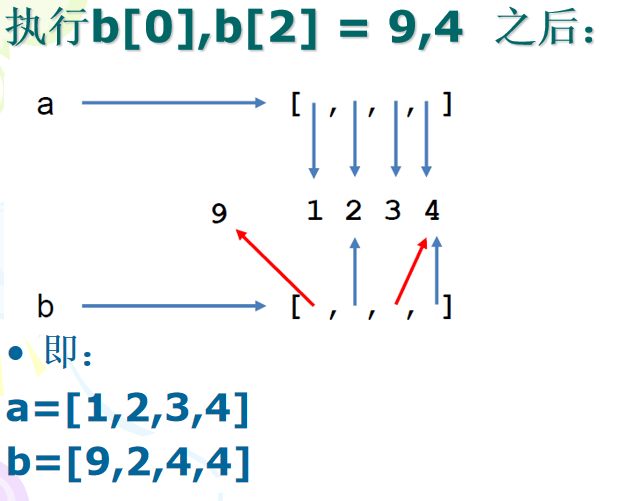
列表是可变的,即可以在不复制的情况下添加、删除或修改列表元素。即列表的元素也是引用。
即:

1、列表的创建
格式:
1 | lst=[元素1,元素2,…元素n] #定义n个元素组成的列表 |
说明:列表用方括号括起,其中元素用逗号分隔。
形式:


2、列表的使用
列表也是序列,其使用与字符串十分相似,同样支持正、负索引、切片等特性,但列表的元素可修改。
与字符串一样,可使用len获取列表长度,还可使用+和*拼接列表。
示例:
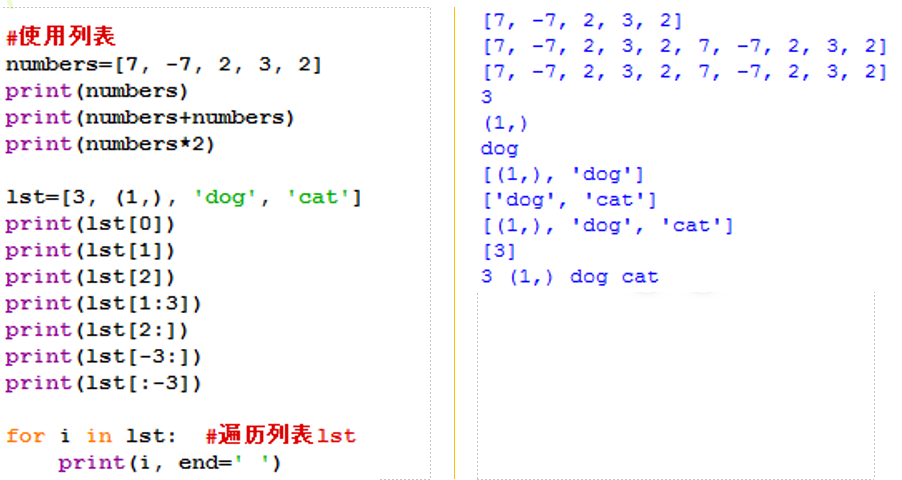
3、列表特有操作及常用方法

示例:
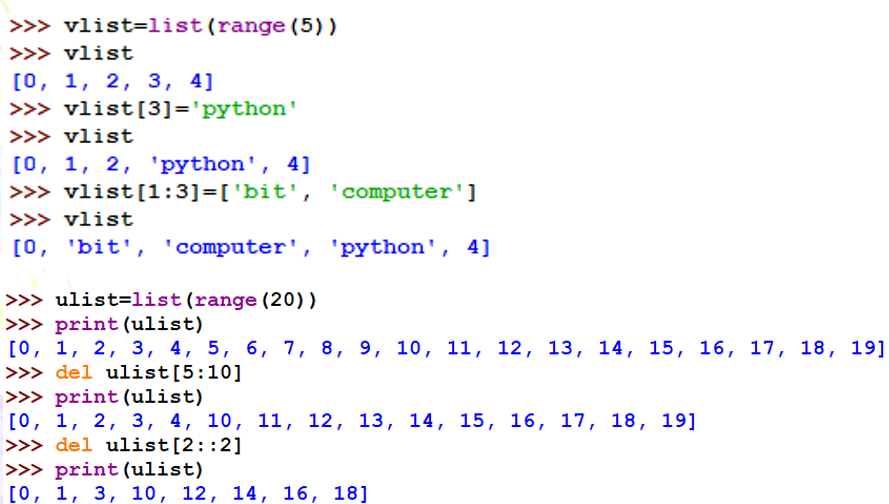
常用方法:
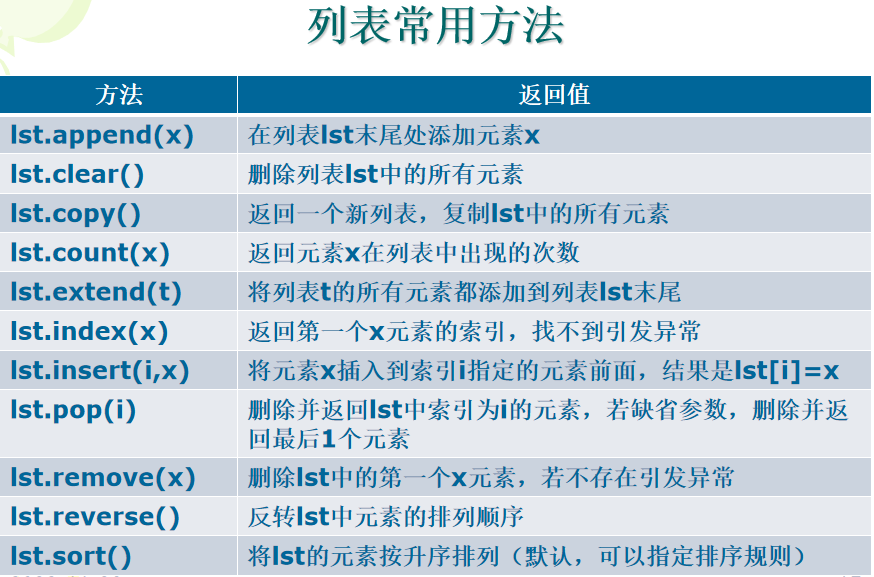
说明:所有适用于序列的函数均适用于列表。调用列表方法之后会改变原列表。列表操作方法的语法形式是:<列表变量>.<方法名称>(<方法参数>)
4、列表用途
- 类似于其他高级语言的数组用途
- 常作为函数的返回类型
元组
元组由一组元素组成。元组可包含任何类型的值:数字、字符串甚至序列;
元组通常代表一行数据,而元组中的元素代表不同的数据项;
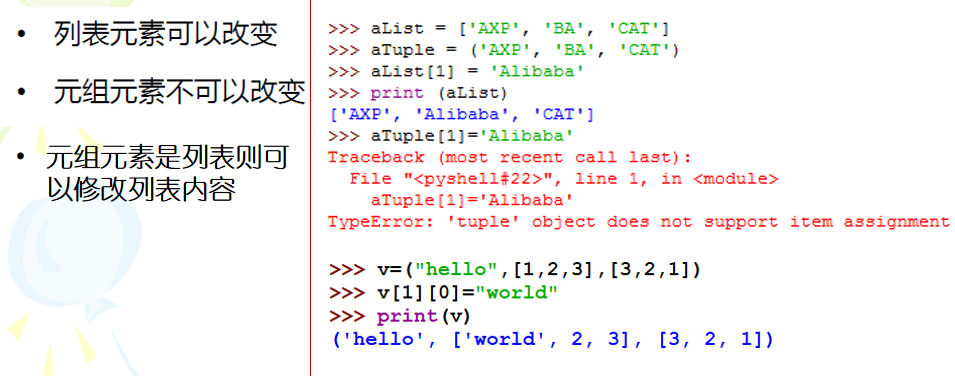
元组是一种不可变序列,即创建之后不能再做任何修改。元组不能修改,指的是不可增删元素,不可对元素赋值,不可修改元素顺序(如排序);
元组的元素都是引用。元组元素不可修改,是指不可改变元组元素的指向,但是元组元素指向的内容,是有可能被修改的。例如,如果元素是列表,就可以修改该列表。
1、元组的创建
格式:
1 | tpl=(元素1,元素2,…元素n) #定义n个元素组成的元组 |
说明:元组用圆括号括起(也可以不加圆括号),其中元素用逗号分隔。
对于sort和sorted:元组不能用sort,但可以用sorted,因为sorted不改变原来的顺序。

2、元组常用方法

说明:所有适用于序列的函数均适用于元组,元组没有列表所常用的append、insert等方法
元组操作方法的语法形式是:<元组变量>.<方法名称>(<方法参数>)
示例:

注意,这里有一行代码:
这里
divisors + (i,):通过将已有的元组divisors与包含当前因数i的元组连接,创建一个新的元组。逗号在(i,)中很重要,它确保创建一个包含单个元素的元组。如果没有逗号,(i)将被视为带有括号的表达式,而不是一个元组。所以元组如果只有一个元素,则需要写成
(item,)这种形式,而不是(item)
3、元组用途
- 在映射类型中当作键使用
- 函数的特殊类型参数
- 作为很多内置函数的返回值
字典
字典是Python重要的数据类型,字典是由“键—值”对组成的集合,字典中的“值”通过“键”来引用。
字典也称为关联数组、映射或散列表。
Python字典利用了“哈希”方法,使用专门的哈希函数完成,即字典中的每个键都被转换为一个数字—哈希值。字典中值存储在一个底层列表中,并用哈希值作为索引。访问值时,将提供的键转为哈希值,再转到列表的相应位置。使用“键”来访问字典值效率极高。
字典的键必须是可哈希对象,可哈希对象是指拥有__hash__(self)内置方法的对象。列表、可变集合和字典类型的数据不是可哈希对象,所以它们不能作为字典中的键。数值、字符串、元组和不可变集合都是可哈希对象,因此可以作为字典的键。与列表相同,字典也是可以改变的,可以添加、删除或修改“键—值”对。字典的排列顺序在v3.5及以前版本不确定,在之后版本取决于创建顺序。
1、字典的创建
格式:
1 | dictionary={key1:value1, key2:value2, …, keyn:valuen} #创建n个“键—值”对组成的字典 |
dict函数的参数说明:参数可以是如下之一:
- 一个或多个赋值表达式
- zip函数返回的结果
- 元组列表,每个元组包含两个元素,分别对应键和值
- 一个已有的字典
示例:

对于字典的键有两个限制:字典中的键必须独一无二,即在同一个字典中,任何两个键—值对都不能相同。若为同一键值多次定义了不同的元素值,按照字典中此键值出现的顺序,只取最右侧的一对“键:值”。键必须是不可变的(可哈希的)。因此,字典的键不能是列表、字典、可变集合。对值没有这两个限制。
例如:
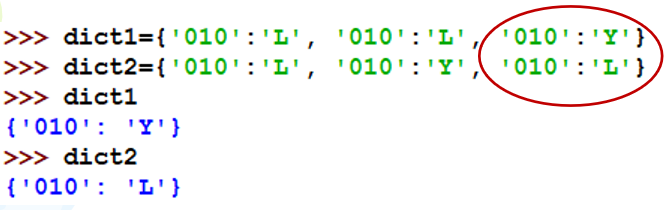
2、字典的访问
字典的访问与元组、列表有所不同,元组和列表是通过数字索引获取对应的值,而字典是通过key值获取相应的value值。格式:
1 | value=dictionary[key] |
说明:字典的添加和修改只需执行一条赋值语句即可,例如:dictionary[x]=value
字典的删除虽没有类似列表的remove操作,但可调用内置函数del()完成删除字典元素(字典带有pop和clear方法,也可以完成删除的功能)。
示例:

3、字典常用方法
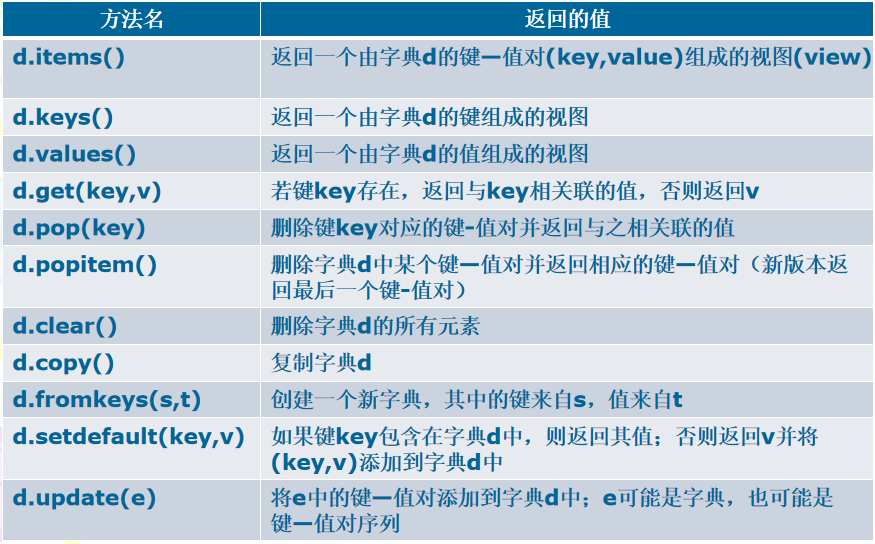
说明:在v3.5及以前版本,popitem()返回并删除字典的某个键-值对,具体是哪个预先并不知道,因此仅当不在乎字典元素的顺序时,此函数才适用;在之后版本,返回并删除的是字典的最后一个键-值对。
items()、keys()和values()都返回一个特殊对象—视图。视图被链接到原始字典,因此若字典发生变化,视图也将相应地变化。
字典操作方法的语法形式是:<字典变量>.<方法名称>(<方法参数>)
示例:

4、字典的排序
字典的排序可以使用内置函数sorted()实现(该函数可对字符串、列表、元组、字典进行排序,都不改变原对象)。
1 | sorted(iterable, key=None, reverse=False) --> new sorted list |
对于字典,此处:
- iterable—字典的键-值对
- Key—排序关键字:键或值
- reverse—升序或降序,True为降序,False为升序,默认升序
示例:

在
sorted(dict1.items(), key=lambda d: d[0])中,dict1.items()返回的是一个视图对象,其中的每个元素都是键值对的元组,类似('d', 'banana')。
key=lambda d: d[0]中的d代表这个键值对的元组,而d[0]表示这个元组的第一个元素,即字典的键。
5、字典应用


集合
在Python中,集合类似于字典,但只包含键,而没有相关联的值。
集合的元素排列顺序不管哪个版本都是不确定的,但不允许有相同元素且元素必须是可哈希(hashable)的对象。可哈希对象是指拥有__hash__(self)内置方法的对象。
列表、可变集合和字典类型的数据不是可哈希对象,所以它们不能作为集合中的键。数值、字符串、元组和不可变集合都是可哈希对象,因此可以作为集合的键。
Python中集合的类别:
集合分两类:可变集合(set)和不可变集合(frozenset)。对于可变集合,可添加和删除元素,而不可变集合一旦创建就不能更改。
在Python中,集合是相对较新的功能,在其还不支持集合时,一般使用字典模拟集合。集合没有列表和字典用得多,本章简要介绍,详细内容可参阅:https://docs.python.org/3/library/stdtypes.html#set
1、集合的创建
集合分两类:可变集合set和不可变集合frozenset。对于可变集合,可添加和删除元素,而不可变集合一旦创建就不能更改。
集合中的所有元素都写在一对大括号“{}”中,各元素之间用逗号分隔。
创建集合时,既可以使用{},也可以使用set函数。
set函数的语法格式:
set([iterable])其中,
iterable是一个可选参数,表示一个可迭代对象(包括:字符串、列表、元组、字典、集合)。set函数只能有一个参数或者无参。注意:想要创建空集合,必须使用 set() 而不是{}。
创建不可变集合
s=frozenset ([iterable])根据给定参数创建不可变集合s=frozenset()创建不可变空集合
示例:创建集合
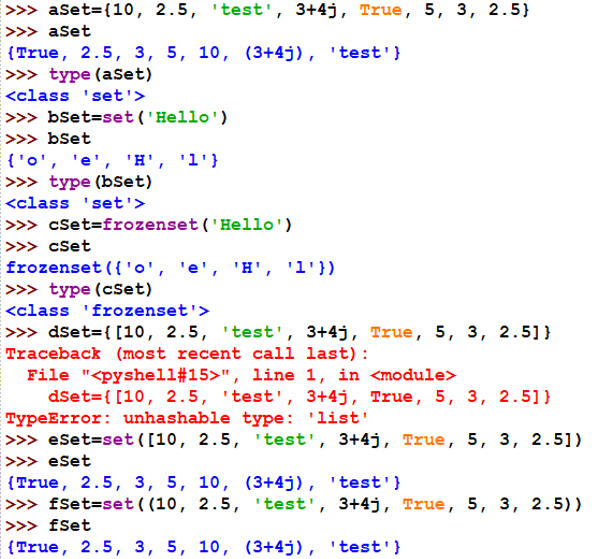
set([iterable]):这个里的参数是可以选择列表的,但是用{}创建集合时,是不能用参数的
2、集合关系运算

3、集合逻辑运算
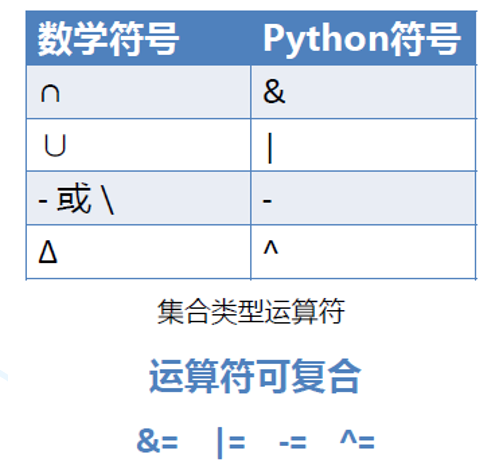
示例:

4、集合的方法
面向所有集合:

面向可变集合:

推导式(生成式)
推导式是从一个或者多个迭代器快速简洁地创建数据结构的一种方法可将循环和条件判断结合,从而避免语法冗长的代码
可以用来动态地生成列表、元组、字典和集合
1、推导式基本语法
- 列表推导式:
[<表达式> for <变量> in <可迭代对象> if <逻辑条件>] - 元组推导式:
tuple(<表达式> for <变量> in <可迭代对象> if <逻辑条件>) - 字典推导式:
{<键值表达式>:<元素表达式> for <变量> in <可迭代对象> if <逻辑条件>} - 集合推导式:
{<元素表达式> for <变量> in <可迭代对象象> if <逻辑条件>}
示例:

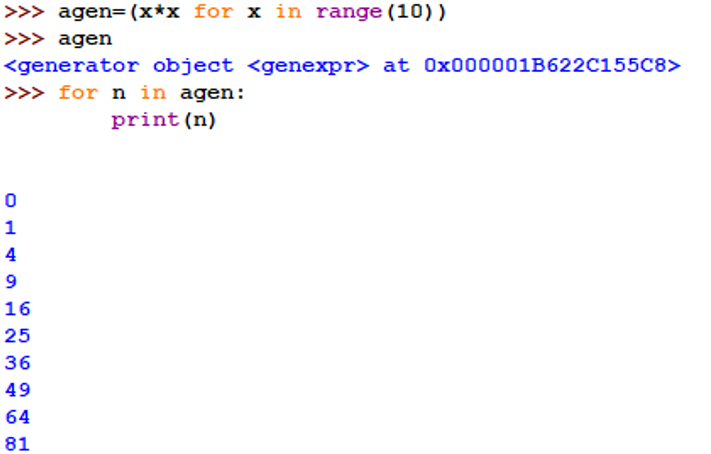
2、生成器推导式
与推导式语法相同: (<元素表达式> for <变量> in <可迭代对象> if <逻辑条件>)
返回一个生成器对象,也是可迭代对象但生成器并不立即产生全部元素,仅在要用到元素的时候才生成,可以极大节省内存
如果生成的序列比较复杂,可使用生成器函数(详见第五章模块和函数)
示例:
3、列表推导式应用实例



迭代器(*)
可迭代对象(Iterable):可直接使用for循环遍历的对象统称为可迭代对象。
迭代器(Iterator):指具有__iter__()方法和__next__()方法的对象,可以通过next函数不断获取下一个值,并不是所有的可迭代对象都是迭代器。
可以使用isinstance方法判断一个对象是否是可迭代对象或迭代器。
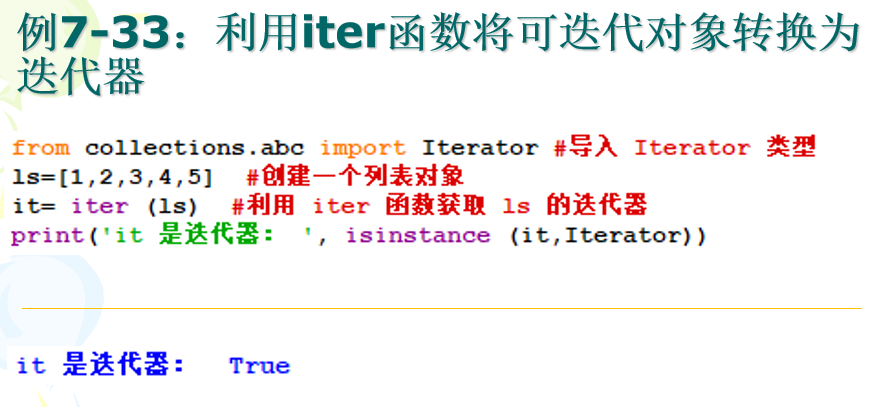
对于可迭代对象,可以通过iter函数得到迭代器。
对于迭代器,则可以使用next函数不断获取下一个元素,当所有元素都获取完毕后再调用next函数,就会引发StopIteration异常。
示例:


可变类型和不可变类型
- 可变数据类型:当该数据类型的对应变量的值发生了改变,那么它对应的内存地址不发生改变,即可以对该类型对象中保存的元素值做修改,如列表、字典、可变集合都是可变类型。
- 不可变数据类型:当该数据类型的对应变量的值发生了改变,那么它对应的内存地址也会发生改变,即该类型对象所保存的元素值不允许修改,只能通过给对象整体赋值来修改对象所保存的数据。但此时实际上就是创建了一个新的不可变类型的对象、而不是修改原对象的值,如数字、字符串、元组、不可变集合都是不可变类型。
说明:
- 可变类型的对象和不可变类型的对象的区别在于是否可修改对象中的元素值。
- 对于可变类型的对象,如果对可变类型对象中的元素做
修改,则不会创建新对象。(但修改后的元素地址会改变) - 对于数字(小整数池)、字符串对象,创建一个新的
等值对象,实际是引用原对象;对于列表、字典、集合等对象,创建一个新的等值对象则是创建一个新对象。 - 对非小整数池整数、元组来说,创建一个新的等值对象的情况存疑?之前的版本是与列表等情况相同,是否因为版本问题不确定。
示例:


(Python中不可变类型包括:数字、字符串、元组、不可变集合,可变类型包括:列表、字典、可变集合)
也就是说,
对于修改操作来说:
- 可变对象,不改变地址
- 不可变对象,相当于创建了新的对象,改变地址
对于赋等值操作来说:
- 数字(小整数池)、字符串对象,不改变地址,这里相当于引用原对象(注意,数字和字符串都是不可变对象)
- 列表、字典、集合、改变地址,相当于创建了一个新的对象(注意,列表、字典都是可变对象)
- 非小整数池整数、元组,因为版本问题不确定
关于复制
复制分为深拷贝和浅拷贝。
- 赋值:简单地拷贝对象的引用,两个对象的id相同。
- 深拷贝:能够拷贝对象内部所有数据和引用,两个对象的id不同。引用相当于C语言中指针的概念,Python并不存在指针,但是变量的内存结构是通过引用来维护的。
- 浅拷贝:并不复制对象内部所有引用,只复制所有数据,两个对象的id不同。
说明:
- 浅拷贝和深拷贝的不同仅仅是对组合对象而言,所谓的组合对象就是包含了其它对象的对象,如列表、元组、字典、类实例等又包含了这些数据类型。
- 对于非组合对象,如:列表中只包含数字或字符串等原子类型的数据,深浅拷贝并无区别,一律生成另一个对象。
- 而对于组合对象而言,浅拷贝的副本肯定是另外一个对象,但其中的元素还是指向相同的对象,也就是说其中的元素还是一份;深拷贝是指创建一个新的对象,然后递归的拷贝原对象所包含的子对象。深拷贝出来的对象与原对象没有任何关联。
- 对于数字、字符串等原子类型对象,无论深浅拷贝生成的都是对原对象的引用。
实现浅拷贝、深拷贝的方法
常见的浅拷贝有:切片操作、工厂函数(list,str,tuple)、对象的copy()方法、copy模块中的copy函数。
可使用copy模块来实现组合对象的深拷贝和浅拷贝。
deepcopy()用于深拷贝copy()用于浅拷贝
示例:

对于非组合对象,如:列表中只包含数字或字符串等原子类型的数据,深浅拷贝并无区别,一律生成另一个对象。
但赋值则稍微不同,是拷贝对象的引用,两个对象的id相同,相当于两个”标签“指向同一个对象,那么一个对象内部元素改变了,两个对象内部当然都改变。


对于组合对象:
- 浅拷贝的副本肯定是另外一个对象,但其中的元素还是指向相同的对象,也就是说其中的元素还是一份。
- 深拷贝是指创建一个新的对象,然后递归的拷贝原对象所包含的子对象。深拷贝出来的对象与原对象没有任何关联。
