梯度下降法(一)
梯度下降法(一)
一、梯度下降的基本思想
咱们先从一个故事开始,话说有三个兄弟被困在了浓雾弥漫的山上,渴得要死,他们的目标是看谁能尽快到山谷中找到水源,由于大雾能见度极,难以确定下山的路径,只能一点点探路决定前进的方向。
老大非常谨慎,全方位观察,综合比较后才选择最陡的方向;
老二随性胆大,随机探一处就朝较低处走去;
老三比较普通,没有大哥小心翼翼,也没有二哥大大咧咧,而是探测几下就走最陡峭的方向。
你觉得谁最有可能先到山脚找到水源呢?
三兄弟下山找水的过程都用到了梯度下降的思想,每走一段路测量出当前最陡的方向,然后向前重复这个过程,就能成功抵达山谷。在这个故事中,大山代表了什么,又该如何确定梯度呢?
二、梯度下降的主要原理
1、确定一个小目标—––预测函数
(ps:也叫目标函数)
机器学习的一个常见任务,就是通过学习算法,然后自动发现数据背后的规律,进而不断改进模型,然后做出预测。
- 学习算法
- 发现规律
- 改进模型
- 做出预测
为便于理解,我们举一个简单的例子:
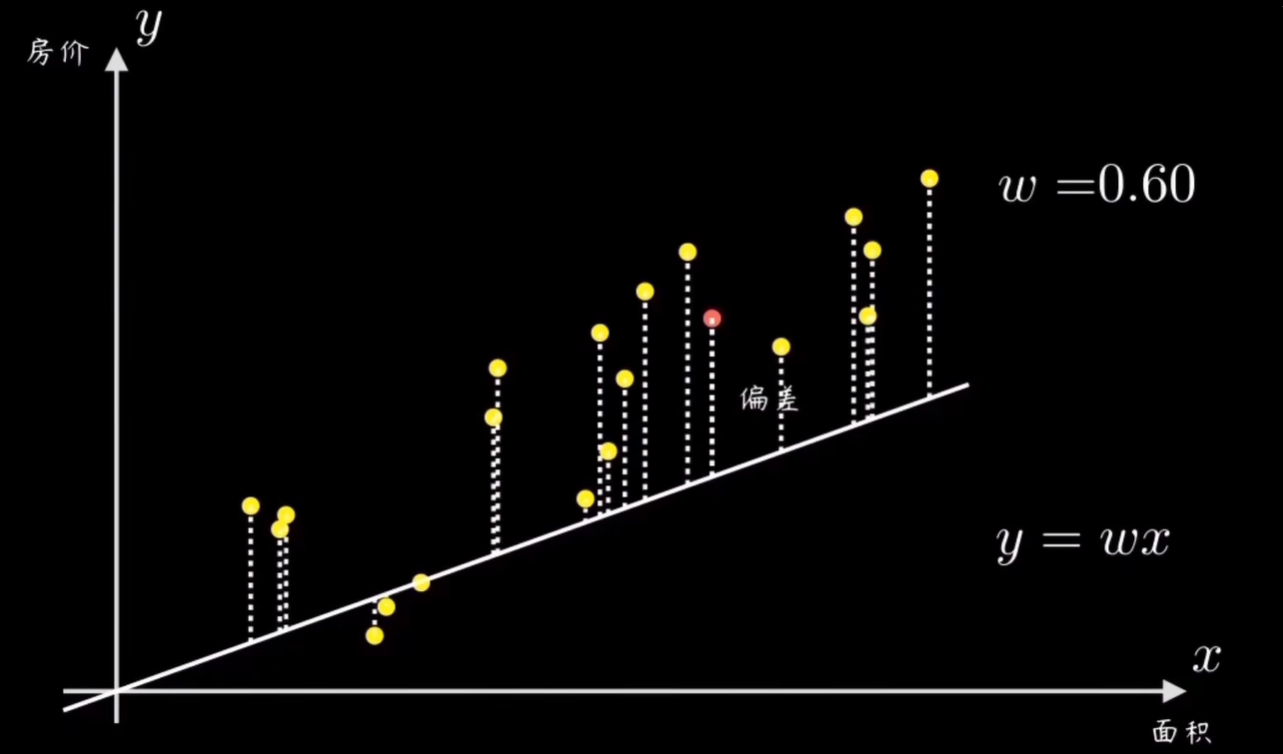
在二维直角坐标系中,有一群样本点,横纵坐标分别代表一组有因果关系的变量,比如房子的价格和面积,人的身高和步幅等等。常识告诉我们,它们的分布是正比例的,也就是一条过圆点的直线。
我们的任务就是设计一个算法,让机器能够拟合这些数据,帮助我们算出直线的参数w。
一个简单的办法就是先随机选一条过圆点的直线(这里只是假设最简单的情况),然后计算所有样本点和它的偏离程度,再根据误差大小来调整直线的斜率w。在这个问题中直线y=wx,就是所谓的预测函数。
.gif)
2、找到差距—––代价函数
(ps:一般情况也叫损失函数,但其实严格上,代价函数和损失函数有一些区别,具体可看最后的参考链接。)
原理我们知道了,如何让计算机实现呢,首先我们需要量化数据的偏离程度,也就是误差,这里我们就是把误差设为点到直线的竖直距离。
最常见的方法是均方误差,顾名思义,就是误差平方和的平均值。(其实这里误差的定义和误差的公式可以根据实际情况来定义,下面可以看到相关公式,其实1/n也有设为1/2或者其他系数,还有的不平方,直接是点到直线的竖直距离的和等待,这么做的目的只是为了方便求导或者计算。)
我们先看一个点P1,它的坐标是(X1,Y1), 对应的误差是e1。
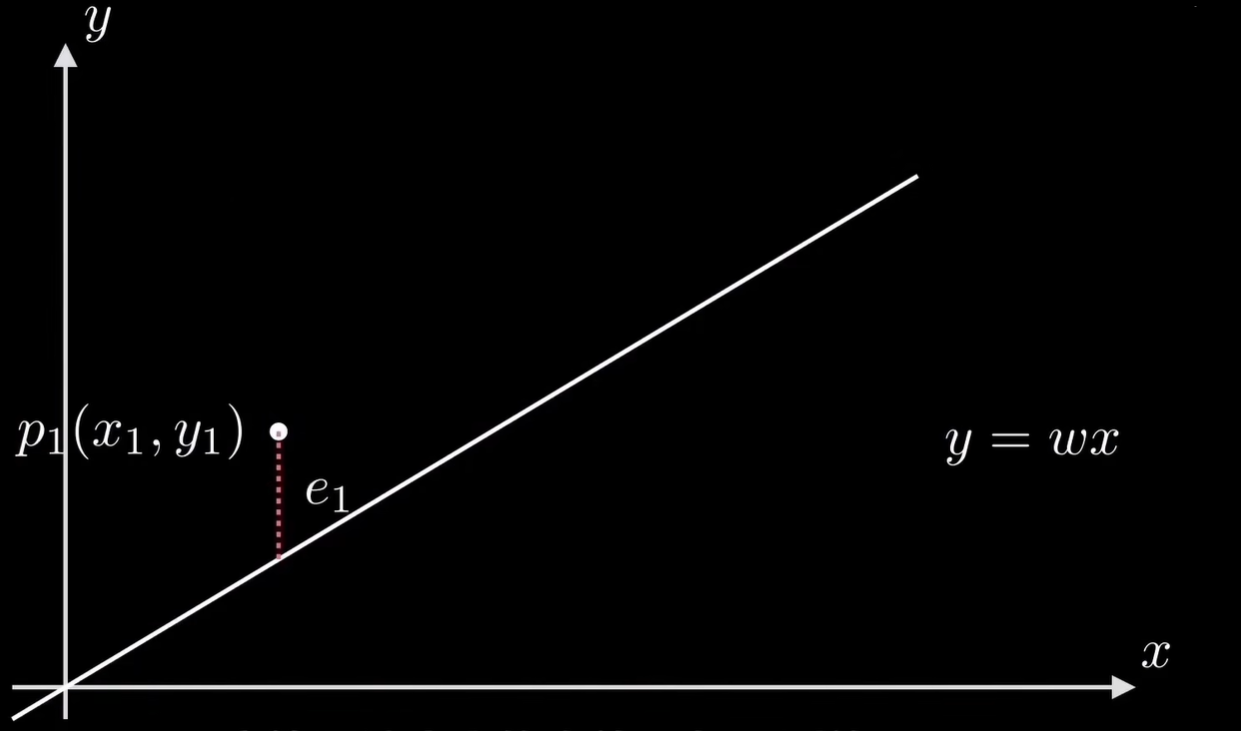
它等于这个点的真值Y1与预测值w乘X1的差的平方:。 \[ e_1=(y_1-w*x_1)^2 \] 用完全平方公式展开就是这样: \[ e_1=x_1^2*w^2-2(x_1*y_1)*w+y_1^2 \] 同理点P2,P3一直到PN的误差E2,E3,一直到EN也都是一样的形式:
\[\begin{gathered} e_{1} =x_1^2*w^2-2(x_1*y_1)*w+y_1^2 \\ e_{2} =x_2^2*w^2-2(x_2*y_2)*w+y_2^2 \\ e_{3} =x_3^2*w^2-2(x_3*y_3)*w+y_3^2 \\ ... \\ e_{n} =x_n^2*w^2-2(x_n*y_n)*w+y_n^2 \end{gathered} \]
我们的目的是求所有点误差的平均值,考虑到x,y和样本数n都是未知数,因此通过合并同类项,然后用常量a,b,c分别代替不同项的系数
我们可以大大简化最终的式子,如此以来,就得到了一个高中学过的一元二次函数:
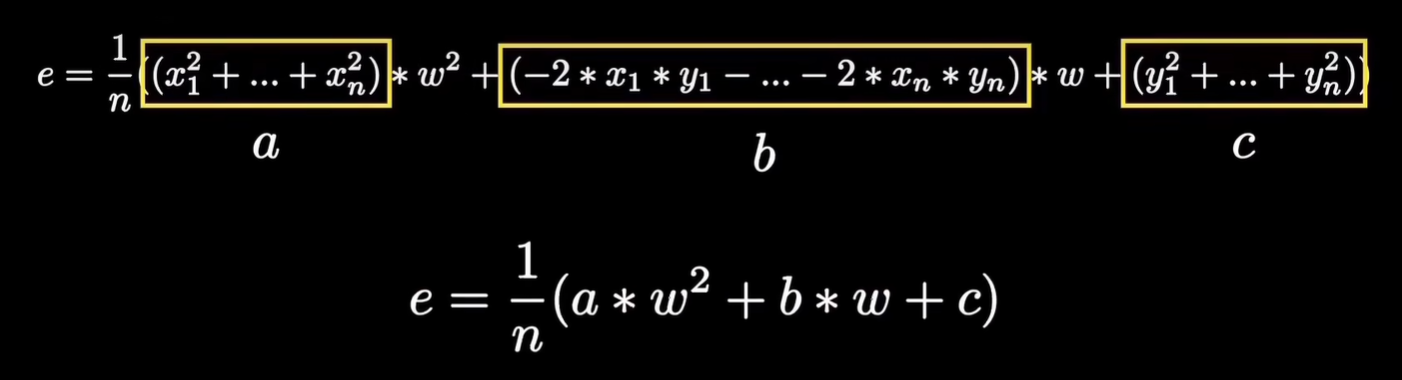
我们也可以把前面的1/n放进去一起设为参数,这个误差函数表示了学习所需要付出的代价,因此常常被称为代价函数。 \[ e=a*w^2+b*w+c \] 当w的取值发生变化时,直线绕圆点旋转,对应到抛物线图像,就是取值点沿着曲线的运动:
.gif)
通过定义预测函数,然后根据误差公式推导代价函数,我们成功地将样本点拟合过程映射到了一个函数图像上。
3、明确搜索方向—––梯度计算
找到了代价函数图像,我们该怎么走呢?
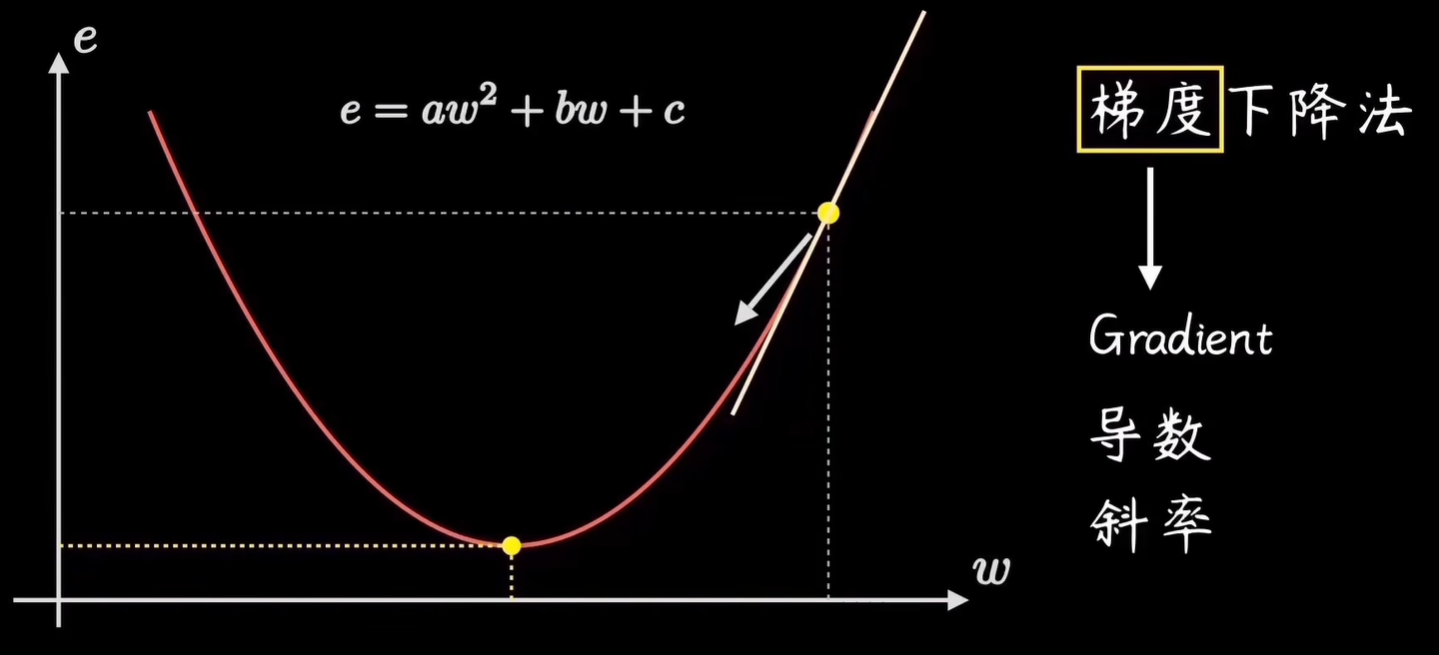
机器学习的目标是拟合出最接近训练数据分布的直线,也就是找到使得误差代价最小的参数w,对应在代价函数图像上就是它的最低点。
这个寻找最低点的过程,就是梯度下降要干的活
假定起始点在曲线上任意一处,直觉告诉我们,只要选择向陡峭程度最大的方向走,就能更快到达最低点。这个陡峭长度就是梯度,英文是Gradient,它是代价函数的导数,对抛物线而言,就是曲线斜率。
4、大胆的往前走吗—––学习率
确定方向以后,就要前进了,但步子该迈多大呢?
假如随便选一个数,比如0.1,那么算法的效果是这样的,可以看到它一直在最低点附近震荡,难以收敛:
.gif)
那如果直接用斜率值作为步长怎么样?
离最低点远时,斜率大,可以快速收敛;
离最低点近时,斜率越小,收敛的就越精准。
听上去不错的点子:
.gif)
可是实际效果却是左右反复横跳(甚至还越来越往上跳),依然无法收敛到最小值:
.gif)
原因是一下步子迈的太大,往上跳是因为我们是设置斜率越大步子越大,导致甚至会往上跳动。
我们把斜率缩小试试,我们让斜率乘以一个非常小的值,比如0.01,再来看看效果:
.gif)
可以看到现在下降得如此顺滑,这个很小的值有一个好听的名字,叫做“学习率”。
通过学习调整权重参数w的方式就是: \[ 新w=旧w-斜率*\boxed{学习率} \]
5、不达目标不罢休—––循环迭代
总结起来,梯度下降法的完整过程,包括
- 定义代价函数
- 选择起始点
- 计算梯度
- 沿着这个方向按照学习率前进
- 重复第三第四步,直到找到最低点
这个流程就是所谓的梯度下降算法。
代价函数、起始点、梯度、学习率
这些都是梯度下降法的核心要素,也是后来各种算法改进的重要方向
三、实际情况没有这么简单
看到这里,你可能会有些疑问,
既然都知道了代价函数就是一个一元二次的抛物线,为什么不用数学手段直接求解呢?
这种求最大值最小值的问题,不是中学数学常见题型吗?
这是因为实际问题中,序列样本的分布千奇百怪,代价函数也可能千变万化,基本上不太可能是一条简单的抛物线。
比如我们的预测函数稍作改动,变成 y=wx+b ,那么代价函数就变成了误差e,关于两个参数w和b的曲面(在梯度下降法(二)的笔记中我会举一个例子):

但这依然是比较简单的情形,因为只有一个最小点。
此外,代价函数还可能会是一条波浪线,当有多个最小点存在时,机器学习的理想目标将是找到最低的那个,也就是所谓的全局最优,而不是局部最优。(梯度下降只能在代价函数是凸函数的情况下才可以找到全局最优,但实际情况大概率都不是凸函数,那既然梯度下降既然不能找到全局最优,为什么还应用广泛,后面笔记我们再进行讨论。)
.gif)
代价函数也可能会是一个起伏不定的曲面,也就是一个二元函数,同样可以用梯度下降来找到二元函数的全局最小值(凸函数)或者局部极小值
.gif)
又或者某种无法用三维图像描述的更复杂的函数。例如房价,除了和面积相关外,还和城市、地段、朝向、政策等等各种因素相关,这个问题当中,代价函数变成十维百维都有可能,将很难可视化的展示出来,但无论有多少维度,都可以通过梯度下降法来寻找误差最小的点(凸函数情况下)。
四、梯度下降法的各种变体
现在回到我们最初的问题,三个兄弟到底谁更有可能先找到水源呢?
实际上他们分别代表了三种不同类型的梯度下降算法:
- 批量梯度下降法––BGD
- 随机梯度下降法––SGD
- 小批量梯度下降法––MBGD
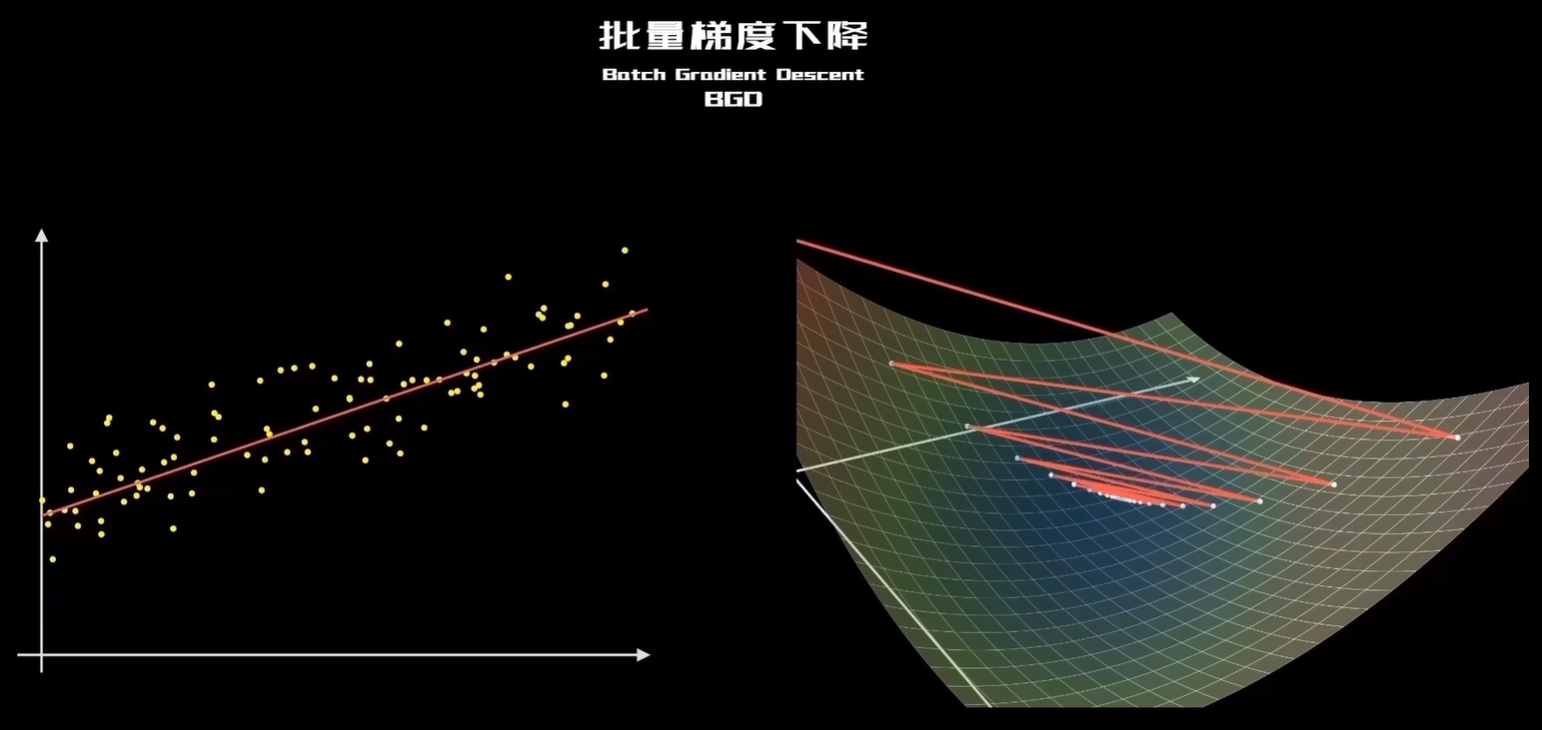
大哥小心翼翼,每次都把四周探测的明明白白的,他的做法就像批量梯度下降法,简称BGD,它的下降过程就像这样
左侧是样本点,右侧是用等高线表示的代价函数曲面,可以看到,它的运算是用全部训练样本参与计算。梯度下降的非常平稳,走出了一条强迫症一般的漂亮曲线。它是梯度下降最原始的形式。好处是能够保证算法的精准度,找到全局最优解(前提是代价函数是凸函数)。但却让训练搜索过程变得很慢,代价很大。
老二大大咧咧,随便探测一下就走的做法,就像随机梯度下降法,简称SGD。它的下降过程顾名思义,非常随性。每下降一步,只需用一个样本进行计算,它的行进路线就像个醉汉,深一脚浅一脚的前进。虽然大方向没错,但下降的非常不平稳,它的好处是提升了计算的速度。但是却牺牲了一定的精准度。(但是该方法反而在实际情况中用的比BGD多)
.gif)
老三结合了老大老二的优点,虽然没有像老大把四周探测的明明白白的,但是也没有像老二随机试探一处,而是多试探几下再走,这种方法叫做小批量梯度下降法,简称MBGD。(这个方法还有个别名,叫最速下降法,从名字看就可见一斑)每下降一步,选用一小批样本参与计算。它的下降过程虽然没有大哥平稳有规律,但是快的多;虽然没有二哥速度快,但准确了很多。走出了一条简洁高效的路线。(这种方法在深度学习中用的是最多的,既能保证准确率,同时速率也不慢)(通常在之前会把样本按设置的批次大小,进行划分,然后每次更新选取其中一个批次的样本,而且通常设置让其每次选取的批次不一样)
.gif)
梯度下降法简单有效,适用范围广,但也并非完美无缺。比如前面讲过,它对学习率的设定非常敏感。
学习率太大,可能会反复横跳,找不到最低点;学习率太小,又会浪费很多的计算量。
.gif)
五、梯度下降的算法调优
在使用梯度下降时,需要进行调优。哪些地方需要调优呢?
- 算法的步长选择。 在前面的算法描述中,我取的步长只是举例子,但是实际上取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否则要增大步长。前面说了。步长太大,会导致迭代过快,甚至有可能错过最优解。步长太小,迭代速度太慢,很长时间算法都不能结束。所以算法的步长需要多次运行后才能得到一个较为优的值。
- 算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因为多数情况,损失函数不是一个凸函数,并且可能有多个局部极小值,因此梯度下降求得的很大概率只是局部最小值。由于有局部最优解的风险,需要多次用不同初始值运行算法,比较损失函数的最小值,选择损失函数最小化的初值。
- 归一化。 如果不归一化,会收敛得比较慢,典型的情况就是出现“之”字型的收敛路径。因为如果不同特征的数值范围差异很大,梯度下降在优化时可能需要花费更多的迭代次数来找到最优解。归一化后,特征值范围相似,优化路径更加平滑,有助于加速收敛;同时归一化还可以减少数值不稳定性(在浮点数计算中,大范围的特征值可能导致数值不稳定,影响优化算法的效果。归一化可以减少这种风险);归一化还可以提高模型性能(一些模型(如SVM、KNN等)对特征尺度敏感,归一化有助于提高这些模型的性能。)这里举一个归一化的例子,例如在特征值服从正态分布的情况下,可以对于每个特征x,求出它的期望和标准差std(x),然后转化为\(\frac{x-\overline{x}}{std(x)}\),这样特征的新期望为0,新方差为1,迭代次数可以大大加快,当然还有更多的归一化方法,这里不做叙述。
六、更优的下山方法
动态调节学习率的AdaGrad,经常更新的参数学习率就小一些,不常更新的学习率大一些,这种方法的一个问题是频繁更新参数的学习率有可能会过小,以致逐渐消失。因此,就出现了解决这一问题的RMSProp算法,以及更高级的,不需要设置学习率的AdaDelta算法,还有融合了Momentum和RMSProp算法的Adam算法。而Momentum算法在下降过程中充分考虑前一阶段下降的“惯性”,这个方法的路线有点像滚下山的样子。此外还有更复杂的FTRL等方法。这些艰深的内容,不是这个笔记的重点,后续如果有研究再更新。

在梯度下降法(二)笔记会讲:
- 在这里我们只是举了一个最简单的例子(一个参数w,因为假设它过原点了,只有斜率参数),在下个笔记我们再举一个二维的例子,直线y=wx+b,那么损失函数就是一个二维的曲面。
- 对于最优问题,凸函数,以及鞍点的一些情况的一些简单理解和介绍。
- 在实际应用中的一些情况,以及各种下山方法的介绍。
- 三种方法的伪代码。
参考:
如何理解随机梯度下降(stochastic gradient descent,SGD)
梯度下降的参数更新公式是如何确定的? - 知乎 (zhihu.com)
最优化问题——梯度下降法 - Christina_笔记 - 博客园 (cnblogs.com)
机器学习必知必会:梯度下降法 - 知乎 (zhihu.com)
One PUNCH Man——梯度下降和全局最优_梯度下降法如何寻找全局最优解-CSDN博客
代价函数,损失函数,目标函数区别 - 知乎 (zhihu.com)
一些数学证明和方法改进:
