梯度下降法(二)
梯度下降法(二)
在上个笔记中我们举的是一维的例子(假设过原点,只有一个斜率,即参数w,所以损失函数只是一个曲线),那么这里我们先来看一个二维的例子(两个参数,损失函数就是一个二维曲面),来通过这整个流程,加深一下理解。
一、二维例子(预测房价)
例子背景
假设你在做房价预测任务的时候,有以下数据集,其中x代表房屋的面积,y代表房屋的价格:
| 房屋面积x(平方米) | 价格y(千美元) |
|---|---|
| 50 | 150 |
| 60 | 180 |
| 70 | 210 |
| 80 | 240 |
我们的任务就是希望找到一个线性模型y=wx+b来预测房价。
初始化参数
首先,我们随机初始化参数,假设w=0,b=0,当然也可以设置别的参数。
定义损失函数
这里我们使用均方误差MSE,作为损失函数,它衡量的是预测值和实际值之间差异的平方的均值,其实在上个笔记的那个一维的例子中,我们也是使用的这个均方误差。(可以按实际需求选择合适的损失函数) \[
J(w,b)=\frac1n\sum_{i=1}^n(y_i-(wx_i+b))^2
\] 这里其实可以看出,这个例子的损失函数是关于w,b两个参数变化的一个二维曲面,而不是之前那个一个参数的曲线,所以这里损失函数的极小值可以想象为在二维曲面的一个山谷点。
计算梯度
梯度是损失函数对每个参数的偏导数,这里有两个参数,所以对于w,b,梯度的计算公式为:
- 对w的偏导数: \[\nabla_wJ=\frac{-2}n\sum_{i=1}^nx_i(y_i-(wx_i+b))\]
- 对b的偏导数: \[\nabla_bJ=\frac{-2}n\sum_{i=1}^n(y_i-(wx_i+b))\]
(从这里其实也可以看出来,之前在笔记一中提到过,有些人在损失函数的定义的时候,把1/n这个系数换成1/2,其实就是在求导的时候方便了计算,虽然不是均方误差,但是方便了计算。具体定义可以根据实际情况来确定损失函数。
具体计算
这里我们使用上面表格中具体的数据来进行计算,来把这个流程过一遍:
对w的偏导数: \[\begin{aligned}&\nabla_wJ=\frac{-2}4[(50)(150-(0\cdot50+0))+(60)(180-(0\cdot60+0))+(70)(210-(0\cdot0)\\&70+0))+(80)(240-(0\cdot80+0))]\\&\nabla_wJ=\frac{-2}4[7500+10800+14700+19200]=\frac{-2}4[52200]=-26100\end{aligned}\]
对b的偏导数: \[\begin{aligned}&\nabla_bJ=\frac{-2}4[(150-0)+(180-0)+(210-0)+(240-0)]\\&\nabla_bJ=\frac{-2}4[780]=-390\end{aligned}\]
参数更新
假设我们选择学习率η=0.0001,然后就可以根据梯度下降的公式来更新参数: \[
新w=旧w-斜率*\boxed{学习率}
\]
更新w: \[w=w-\eta\cdot\nabla_wJ=0-0.0001\cdot(-26100)=2.61\]
更新b: \[b=b-\eta\cdot\nabla_bJ=0-0.0001\cdot(-390)=0.039\]
重复迭代
重复计算梯度和更新参数的步骤,直到梯度接近零或达到一定的迭代次数,从而使损失函数J最小化。这个过程中,w和b会逐渐调整到能够较好地预测房价的值。通过这个具体计算的二维例子,就可以看到,梯度下降算法通过计算偏导数(即梯度),然后在梯度指向的方向上来调整参数。
小思考
在梯度计算完成后,更新参数时,为什么都是-指定参数的梯度?
其实很容易理解,我们先来分析梯度的符号、方向以及如何理解梯度指向损失增长最快的方向:
1、梯度的符号
当我们说梯度是损失函数增长最快的方向时,指的是如果你沿梯度正方向移动参数,损失函数的值会增加最快。因此,梯度实际上指向了局部最大点的方向。但在优化问题中,我们通常想要找到损失函数的最小值,这就是为什么我们要沿着梯度的反方向更新参数。 举个例子:假设某一点的梯度计算结果为正数(例如\(\frac{\partial J}{\partial w}=10\))。这意味着如果增加w,损失函数J会增加。但我们的目标是减少J,所以我们应该减少w的值。这就是更新公式中存在“减号”的原因: \[
w=w-\eta\times10
\] 那如果是负数呢,梯度如果是负数,例如\(\frac{\partial J}{\partial w}=-10\),这意味着减少w会增加J。因此,为了减少J,我们应该增加w,但是由于梯度是负数,我们使用减法,就相当于增加了w,所以这里依然是使用“减号”: \[
\begin{gathered}
w=w-\eta\times(-10) \\
w=w+\eta\times10
\end{gathered}
\] 所以,不管梯度的符号是什么,“减去 η 乘以梯度” 这个操作总是让我们向减少损失的方向移动。
2、梯度的方向
由于梯度指向损失增长最快的方向,如果我们想最小化损失,就应该向相反方向移动。这就是为什么更新公式中会减去学习率*梯度,这里学习率控制着我们沿着梯度反方向移动的步长。正确选择学习率是关键。
3、关于初始值以及SGD更新的理解
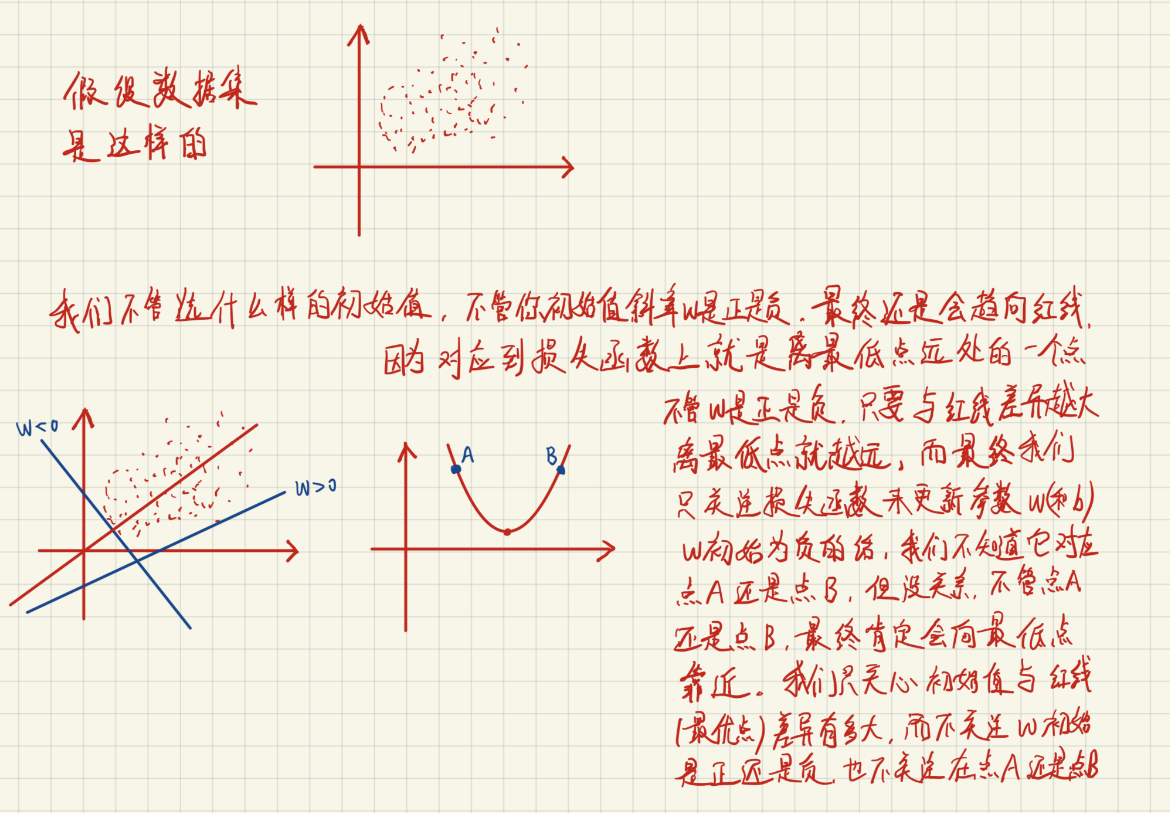

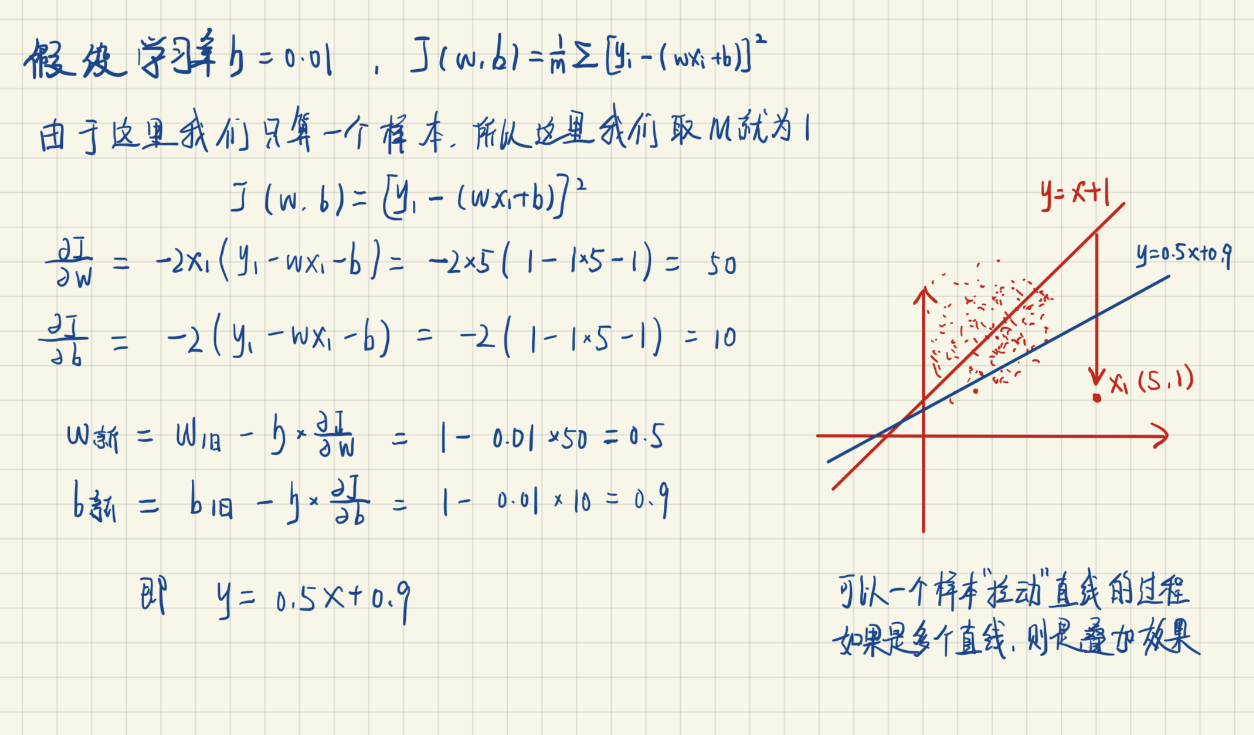
再观察SGD的这个动态图,就理解了每个样本其实都是“拉动”直线向其靠近:
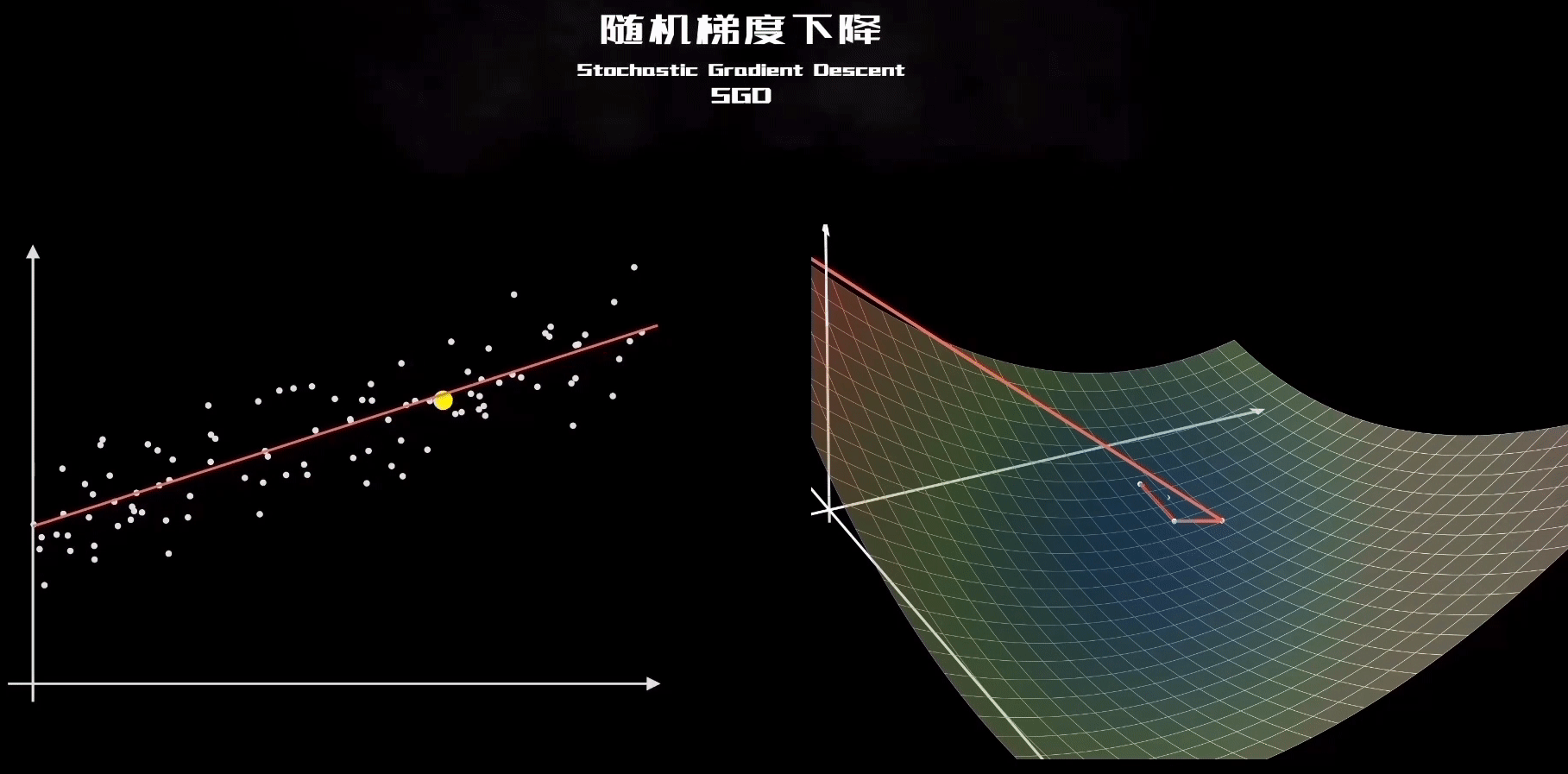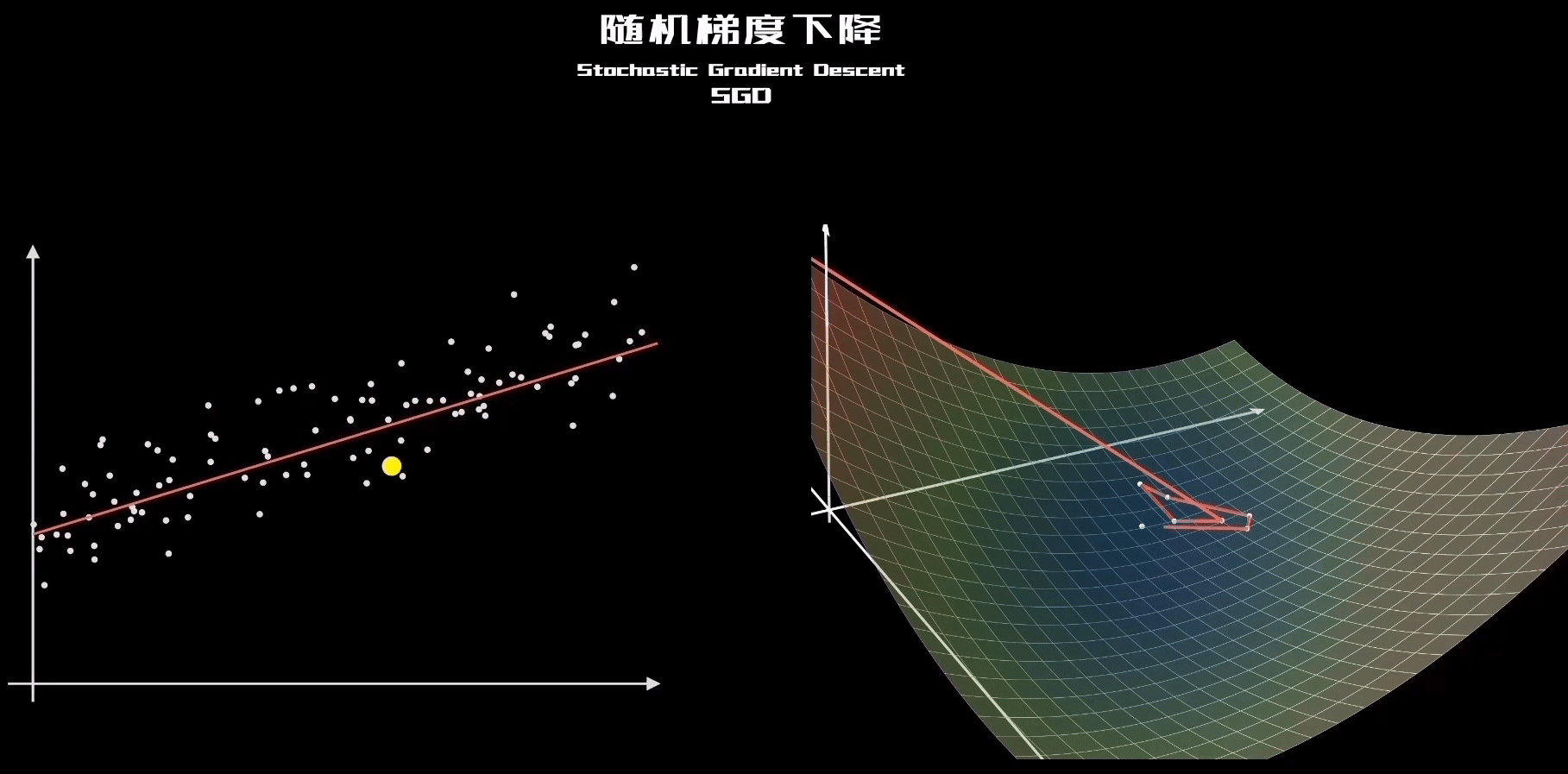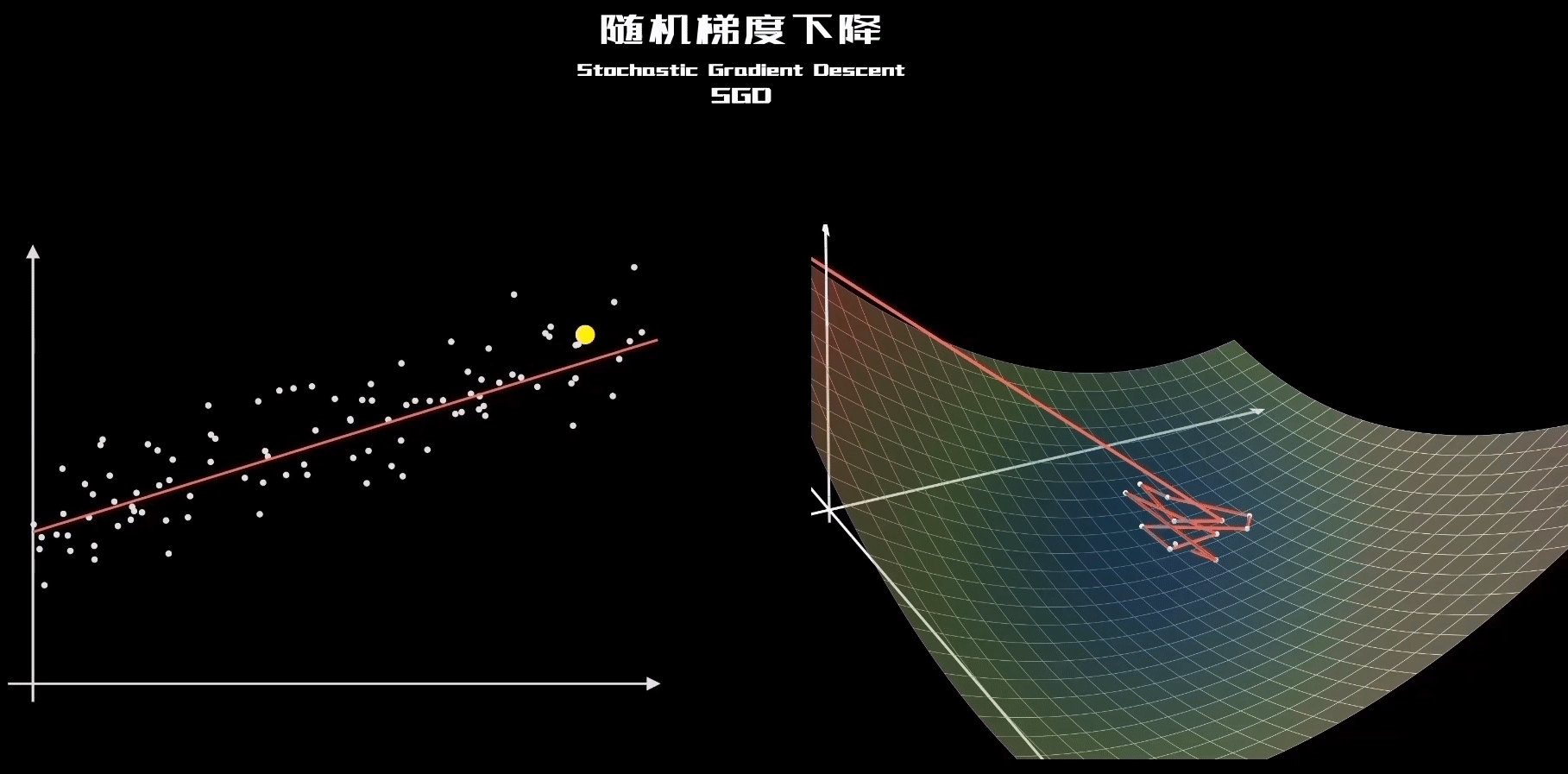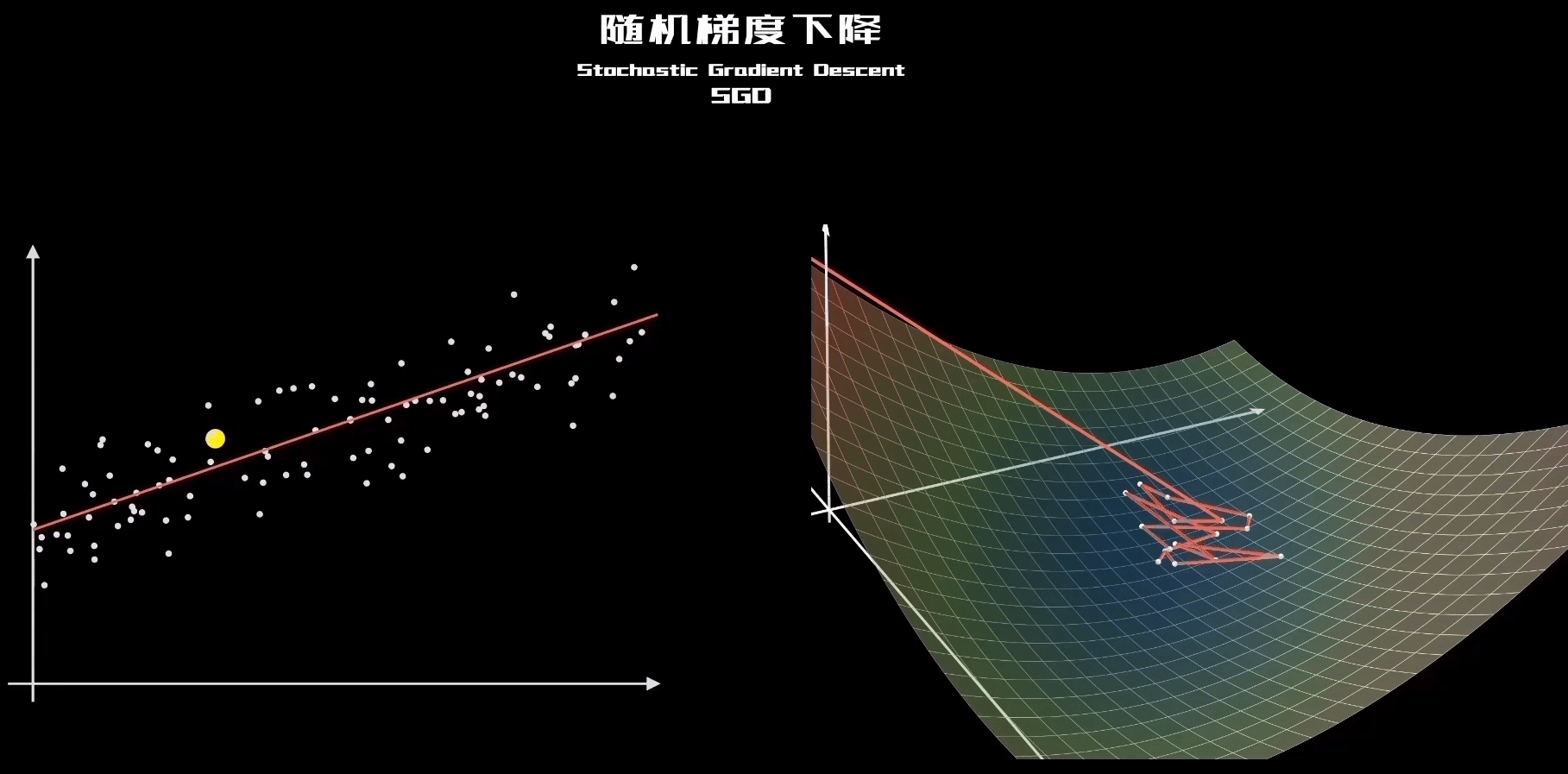
二、全局最优和局部最优的理解
在前面笔记(一)中我们提到了梯度下降法的基本思想和方法,也介绍了梯度下降法的几个类型,现在我们再来回顾一下并更加深入的理解一下BGD,SGD,MBGD三种方法。
我们先回答一下上个笔记中遗留下的一些问题:
1、问题一
为什么批量梯度下降法BGD可以在凸函数问题中找到全局最优解,而随机梯度下降法SGD和小批量梯度下降法MBGD即使在凸函数中也不一定能找到全局最优解呢?
其实理论上是这样的,我们知道批量梯度下降BGD是在每次更新参数的时候计算所有样本的,也就是所有样本都参与更新参数的计算中,显然在凸函数问题中,理论上是可以找到全局最优的。但是随机梯度下降SGD呢,它只是在每次更新时用1个样本,这里注意多了“随机”两个字,也就是随机用一个样本来近似我所有的样本,来调整参数,因而随机梯度下降是会带来一定的问题,因为计算得到的并不是准确的一个梯度,这里的不准确指的是,虽然不是每次迭代得到的损失函数都向着全局最优方向,但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。其实在上个笔记那个动图就可以看到,SGD它可能一直在全局最优解附近“振荡”或者说“跳跃”,因为它每次都是随机选一个,所以不保证就一定是全局最优解,所以关键点在这里,并不是说它就不能得到全局最优,只是说因为随机选取一个的原因,导致它可能不是很能稳定收敛下来。
所以理解了这个,其实梯度下降这三个类型的方法,理论上都可以在凸问题中找到全局最优解,只不过SGD和MBGD由于样本的随机和只选取一部分或一个样本的原因,导致可能不能在全局最优点稳定的收敛下来,SGD是在全局最优点附近“振荡”,但是相比于批量梯度BGD,这样的方法更快,更快收敛,虽然不是全局最优,但很多时候是我们可以接受的,而且比BGD用的更多。而MBGD呢,在每次更新时用b个样本,其实小批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是我1个指不定不太准,那我用个30个50个样本那比随机的要准不少了吧,而且小批量的话还是非常可以反映样本的一个分布情况的。在深度学习中,这种方法用的是最多的,因为这个方法收敛也不会很慢,收敛的局部最优也是更多的可以接受,这里也一样,由于小批量的样本和批次选取的问题,导致也可能在全局最优附近波动(MBGD是先把数据分批次划分,然后选取批次的时候,这个有人设置成随机选取批次,也有人设置为选取的批次只能选一次,也就是每个批次选取一次),但是相比SGD要稳定很多,离所谓的全局最优也更加接近。
总的来说,梯度下降法三种:BGD、SGD、MBGD理论上都可以在凸问题中得到全局最优解,只不过后两种SGD和MBGD,它们两由于更新参数时,选取样本的随机性和样本的部分性,导致可能不能在全局最优点稳定的收敛下来,而是在全局最优点附近“振荡”,这只是一个概率问题。(MBGD其实大部分情况已经非常接近全局最优了,速度也快,所以用的最多)
实际情况中,我们通常很少遇到凸问题,基本都是有多个局部最优,但是MBGD也用的很多,同样的道理,MBGD大部分情况已经非常接近局部最优了,速度收敛也快,所以用的多。SGD在实际情况中还有个优点,就是它的频繁更新可能导致嘈杂梯度,但这也有助于避开局部最小值,找到全局最小值。而在BGD中,虽然这种批量处理提高了精确度,但对于大型训练数据集而言,它仍然需要很长的处理时间,因为仍要将所有数据存储到内存中。BGD算法通常也会产生稳定的误差梯度和收敛性,但有时在寻找局部最小值和全局最小值时,收敛点并不是最理想。而SGD为数据集中的每个示例运行一个训练周期,并一次性更新所有训练示例的参数。 由于只需保存一个训练示例,所以可以更轻松地将它们存储在内存中。
2、问题二
那既然梯度下降通常不能找到全局最优,为什么还应用广泛呢?
我们知道,梯度下降法只能在凸问题上才能找到全局最优解,但是实际情况中,几乎很少遇到损失函数是一个凸函数,大多数都不是一个凸函数,可能有很多个局部最优解,既然这样,那为什么梯度下降法还很流行呢?其实就一个原因,因为它在实际情况中是好用的。有一个现象存在:这里我们机器学习的最终目标,不是优化算法跑的多准,而是学习的参数在测试集中要表现好。我们训练的数据集并不能代表全部的测试数据,只能是测试数据的一部分代表,并不是百分之百代表,所以我们用梯度下降法本身的目标就不是找全局最优解 ,因为即使找到了全局最优解,它在测试集上也有可能表现的很差,它只是在训练集上表现的非常好,在训练集上的全局最优其实就“相当”于overfit了,也就是过拟合,但其实这里说的有点过于绝对了,所以我打了引号,只是告诉在实际情况中可能根本没必要全局最优。(什么情况不过拟合呢,最好的就是在训练集和测试集上表现一样,但是实际上也是基本不可能表现一模一样的)。该方法应用广泛的另外一个原因就是性能好,收敛速度很快,特别是在测试参数很多而算力又很稀缺的时候。
3、关于鞍点
如下图:就像一个马鞍一样,所以称作鞍点:
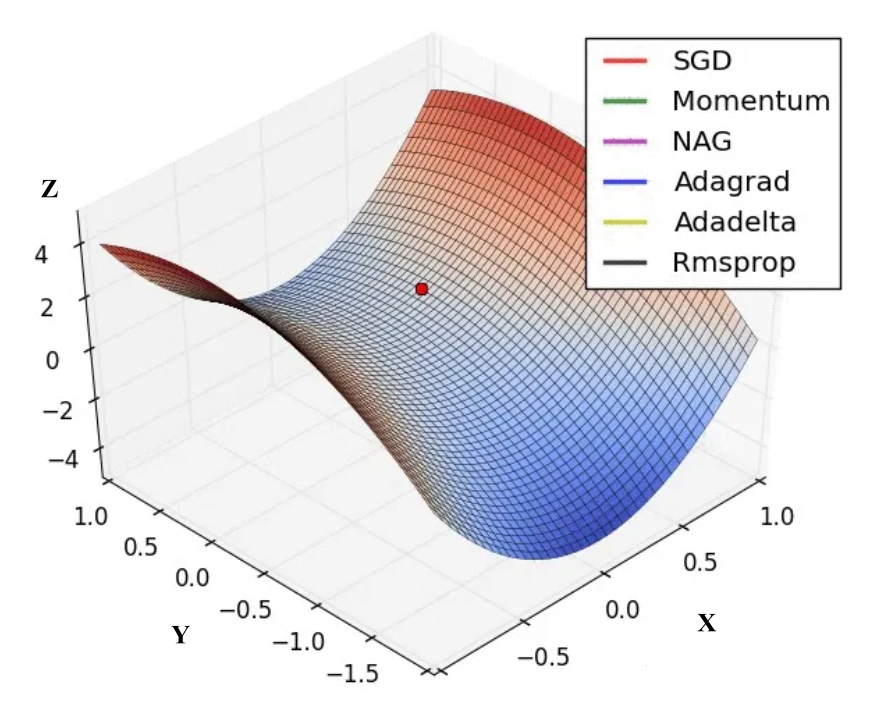
鞍点是最优化问题中常遇到的一个现象,鞍点的数学含义是:目标函数在此点的梯度为0,但从该点出发的一个方向存在函数极大值点,而另一个方向是函数的极小值点。在高度非凸空间中,存在大量的鞍点,这使得梯度下降法有时会失灵,虽然不是极小值,但是看起来确是收敛的。在实际情况中,几乎不存在找到鞍点的可能,除非很碰巧,因为梯度下降是对损失函数每个维度分别求极小值,即分别求J(θ)关于θ1,θ2...θn极小值。例如上图,是一个二维曲面,所以有两个维度(参数),假设为θ1为X方向(维度)的参数,θ2为Y方向(维度)的参数,我们目标就是求J(θ)关于θ1,θ2的极小值,可以看到,在上图这个二维曲面中,鞍点在X方向的梯度为0,在Y方向的梯度也为0,但是鞍点在X方向是极小值,在Y方向是极大值。所以说除非在更新θ1的时候,θ1收敛到梯度为0的时候,θ2也恰好在处在梯度为0的地方,才可能收敛到鞍点(停止更新),不然如果θ1收敛到梯度为0的时候,θ2不在梯度为0的地方的话,即使θ1收敛到极小值,θ2还是会继续更新的(没有停止更新),因为在鞍点在θ2这个参数(维度)中是极大值。
也就是说,在更新参数的时候,θ1(代表X方向)是朝着极小值更新的,最终收敛到X方向的极小值,而θ2(代表Y方向)也是朝着极小值更新的,最终收敛到Y方向的极小值,但是对于上图中的鞍点,在Y方向确是极大值,所以要想收敛到鞍点,显而易见只有当X方向收敛到极小值的同时,Y方向“处在”最大值,(注意用词,这里没有说收敛到极大值,因为我们是收敛到极小值。)只有这种情况下,X方向和Y方向,也就是θ1和θ2由于梯度为0,导致停止迭代更新,从而”收敛“或者说”找到“到鞍点,只要θ2在θ1收敛到最小值的同时,不处在极大值,那么θ2由于会继续向梯度减小的方向迭代更新,就会离鞍点越来越远,就不会到达或者说“收敛”到鞍点了
所以说找到鞍点的很碰巧,因为在高度非凸空间中,虽然可能存在大量鞍点,但要想找到鞍点,必须所有参数的梯度为0,这种情况只有极小概率,但是有没有可能确实收敛到鞍点了呢,毕竟极小概率事件也不能绝对不发生,所以我们在之前笔记提到过,在梯度下降的算法调优中,我们需要多次用不同初始值运行算法,这样也有效避免了该问题。
4、参考文章中提到的一些问题
这里把一个知乎上文章中提到的一些问题拿出来整理一下,虽然有的还有点还不太明白,最优化问题,凸问题是一个很复杂,数学理论很多的问题,甚至有专门的一本书来说关于凸问题的一些理论和数学证明,所以这里我们还没深入学习,只是有目前的一些理解来加深梯度下降算法。
收敛性,能收敛吗?收敛到什么地方?
对于收敛性的问题,知乎上就有这个问题:为什么随机梯度下降方法能够收敛?,我比较赞赏李文哲博士的回答(推荐一看),总的来说就是从expected loss用特卡洛(monte carlo)来表示计算,那batch GD, mini-batch GD, SGD都可以看成SGD的范畴。因为大家都是在一个真实的分布中得到的样本,对于分布的拟合都是近似的。那这个时候三种方式的梯度下降就都是可以看成用样本来近似分布的过程,都是可以收敛的!
对于收敛到什么地方:
能到的地方:最小值,极小值,鞍点。这些都是能收敛到的地方,也就是梯度为0的点。
当然,几乎不存在找到鞍点的可能,除非很碰巧,因为梯度下降是对损失函数每个维度分别求极小值,即分别求J(θ)关于θ1,θ2...θn极小值。
然后是最小值和极小值,如果是凸函数,梯度下降会收敛到最小值,因为只有一个极小值,它就是最小值。
三、BGD、SGD、MBGD的伪代码
这里只是解释一下后面三个算法代码中的x,y是什么:
1 | import numpy as np |
批量梯度下降BGD
关键点在于计算梯度的式子,注意,虽然BGD是每一次迭代计算所有的样本,但实际上,我们可以把样本全部放在一个矩阵里,然后运用矩阵乘法和矩阵转置等运算,就可以一次性用所有的样本求梯度。
1 | m = len(x_b) # 样本数量 |
随机梯度下降SGD
1 | m = len(x_b) # 样本数量 |
这里需要强调和说明的是,我们在前面理论中,说SGD是每次迭代,都是随机使用一个样本来计算梯度, 然后更新参数,但实际上,在下面代码里,你会发现一个问题,就是每一次迭代内部还有一个循环,既然SGD是每次迭代使用一个随机样本来计算梯度,为什么还有一个内层循环呢,直接随机选一个样本计算不就可以吗,为什么要用这个内层循环?我们先来分析这个内层循环的代码做了什么事:
可以看到就是随机从样本集中选取xi,yi这个样本,然后直接用这个样本计算梯度,并更新参数,而这就已经完成了我们前面说的SGD的一个迭代所做的事,而这个内层循环for i in range(m)是把这个事循环执行了m次(m也就是全部样本数)。其实这里我们能更加深入的理解SGD这个算法。
虽然每次运算只使用一个随机选取的样本来更新参数,但通过 m 次运算可以确保在一个迭代周期(epoch)内,所有样本都至少有机会被选中进行一次参数更新。这就是 SGD 的特性:逐样本更新参数,并通过多次迭代周期来覆盖整个训练集。在每个迭代周期内,重复上述过程 m 次,确保所有样本都有机会影响参数更新。通过这种方式,虽然每次参数更新只使用一个随机样本,但在每个迭代周期内进行 m 次运算可以确保所有样本在多次迭代周期内都对模型参数产生影响。这种逐样本更新参数的方法有助于提高模型的收敛速度,同时增加了更新过程的随机性,有助于跳出局部最优解。
我们试想一下,如果就按一层循环,也就是一个迭代周期里,只是随机用一个样本来计算梯度,由于随机性的原因,拟合的直线会不会跳来跳去,或者也有可能,本来可能拟合的不错,然后由于最后几次迭代,选取的样本都是边缘的样本(也就是远离密集中心的),导致拟合的直线又偏离了最优的地方(虽然有学习率,也就是步长,导致每一次更新参数步子不会迈的很大),而且一般样本数量是远大于迭代次数的,比如样本数量有10000个,而迭代次数我们设置100或者1000次,当然这只是举例,迭代次数你也可以设置成10000次,但是我们这里强调的是,样本数量一般是比迭代次数大的,那么在这种情况下,如果每次迭代只选一个随机样本来进行计算,并更新参数的话,那我们迭代完成之后,都没有把样本遍历一边,10000个样本,迭代100次,我们只用了其中随机的100个样本,那这样的效果显然是非常差的。所以这里使用这个内层循环的意义就在于:
- 全面覆盖训练集: 通过在每个 epoch 中遍历所有样本,确保每个样本在每个迭代中都能影响参数更新。这样可以确保在每个 epoch 中所有样本都对参数更新有贡献。
- 遍历所有样本的主要目的是确保在每个迭代周期中,所有样本都对模型参数的更新有贡献。通过这种方式,模型能够更全面地学习训练数据中的模式。虽然每次更新只用到了一个样本,但通过多次迭代周期,模型能够逐渐收敛到较优的参数值。
- 虽然在每个迭代周期中我们遍历了所有样本,但实际每次参数更新只使用一个随机选取的样本。这种方式确保了每个样本在多个迭代周期中都能影响参数更新,从而提高模型的收敛性和鲁棒性。内层循环的作用是遍历所有样本,确保每个样本都能在每个迭代周期中至少被选中一次进行参数更新。
另外,可以发现,其实BGD和SGD在一个循环周期似乎做了同样次数的计算,BGD是一次性计算所有样本(通过矩阵乘法),而SGD虽然每次都只是计算一个样本,但它每个循环周期内都循环了m次(样本数),那这样相当于是,BGD是一次计算100次,SGD是一次计算1次,但是循环100次,那么为什么SGD更快呢?(因为看起来计算量是一样的,而且SGD还是分开算的)
下面的回答供参考:
- 每次更新计算量小:
- 在 SGD 中,每次更新参数只需要计算一个样本的梯度。虽然总的计算量(一个周期内的所有样本)和 BGD 相同,但每次计算的规模要小得多,因此每次更新的速度更快。
- 更快的迭代周期:
- 由于每次更新的计算量小,SGD 可以进行更多的迭代周期,在相同时间内进行更多次参数更新,从而更快地逼近最优解。
- 在线更新和实时学习:
- SGD 可以实现在线更新,即每收到一个新的数据点就可以更新模型参数。这使得 SGD 特别适用于实时数据和流数据场景。
SGD 的这些特性使得它在处理大规模数据时更具优势,特别是当计算资源有限或需要实时学习时。而对比BGD,BGD对于大规模数据集,计算整个训练集的梯度会非常耗时。
总结
- BGD:在每个迭代周期中计算所有样本的梯度,然后更新参数一次。每次计算量大,但更新稳定。
- SGD:在每个迭代周期中,逐个样本计算梯度并更新参数。每次计算量小,但更新频繁且带有随机性。
这种理解方式帮助我们认识到 SGD 尽管在每个迭代周期内计算了 m 次,但由于每次计算的规模小,整体效率更高,尤其在处理大规模数据集时更具优势。
小批量梯度下降MBGD
1 | n_iterations = 50 # 总共进行50个epoch |
这里可以看到对于MBGD也是有一个内层循环,和SGD是一样的逻辑,只不过这里是循环“批次个数”遍。如果没有内层循环,也就是如果每个 epoch 只使用一个小批量的数据,那么大部分数据都不会被用到,模型的训练效果会非常差。其实和SGD是一样的逻辑。SGD可以看成是1个小批次里只有1个样本(minibatch_size = 1)。
这里说一下MBGD的内层循环的逻辑:for i in range(0, m, minibatch_size)
假设你有一个数据集,有 100 个样本,minibatch_size = 20也就是一个小批次有20个样本,那么批次数就是5。
range(0, m, minibatch_size)的意思是,从0到m-1,步长是minibatch_size,也就是20,即内层循环要循环5次,i每次循环分别取:0,20,40,60,80
那么刚开始i=0时,下面两行代码取的是,0~19号样本,做为一个小批次,然后计算梯度,更新参数。
1 | xi = x_b_shuffled[i:i + minibatch_size] # 取出一个小批量的样本 |
循环完了之后呢,i=20,然后就是取20~29号样本,做为一个小批次,然后计算梯度,更新参数,之后就是i=40,取40~59,就这样一直分组计算……..直到把所有样本按批次计算一遍。这样一次迭代(外部循环epoch)就完成了,和SGB一样,也是一个迭代周期把所有样本计算了一遍,只不过这个是分组,然后按批次,一批批计算,说白了,SGD可以看成一个批次里只有一个样本(minibatch_size = 1)
内层循环执行5次,5个批次全部计算一遍,更新一遍参数,这样一次迭代(外部循环epoch)就完成了,然后再执行下一次迭代(外部循环epoch),下一次迭代再重新打乱一下样本的顺序号,然后再分0~19,20~39,40~59…
参考:
如何理解随机梯度下降(stochastic gradient descent,SGD)? - 知乎 (zhihu.com)
梯度下降的参数更新公式是如何确定的? - 知乎 (zhihu.com)
最优化问题——梯度下降法 - Christina_笔记 - 博客园 (cnblogs.com)
